我已经计算了桥梁的荷载,我想使用最大似然估计将 Gumbel 分布拟合到其中最高的 20%。我需要帮助计算分布参数。我已经通读了 scipy.optimize 文档,但我无法理解如何在其中应用函数来估计两个参数函数。
这里有一些理论可能会有所帮助: 有两个似然函数(L1 和 L2),一个用于高于某个阈值 (x>=C) 的值,一个用于低于 (x < C) 的值,现在最可能的参数是两个函数 max 之间相乘的最大值(L1*L2)。在这种情况下,L1 仍然是概率密度函数值在 xi 处的乘积,但 L2 是超过阈值 C 的概率 (1-F(C))。
这是我写的一些代码:
non_truncated_data = ([15.999737471905252, 16.105716234887431, 17.947809230275304, 16.147752064149291, 15.991427126788327, 16.687542227378565, 17.125139229445359, 19.39645340792385, 16.837044960487795, 15.804473320190725, 16.018569387471025, 16.600876724289019, 16.161306985203151, 17.338636901595873, 18.477371969176406, 17.897236722220281, 16.626465201654593, 16.196548622931672, 16.013794215070927, 16.30367884232831, 17.182106070966608, 18.984566931768452, 16.885737663740024, 16.088051117522948, 15.790480003140173, 18.160947973898388, 18.318158853376037])
threshold = 15.78581825859324
def maximum_likelihood_function(non_truncated_loads, threshold, loc, scale):
"""Calculates maximum likelihood function's value for given truncated data
with given parameters.
Maximum likelihood function for truncated data is L1 * L2. Where L1 is a
product of multiplication of pdf values at non-truncated known values
(non_truncated_values). L2 is a the probability that threshold value will
be exceeded.
"""
is_first = True
# calculates L1
for x in non_truncated_loads:
if is_first:
L1 = gumbel_pdf(x, loc, scale)
is_first = False
else:
L1 *= gumbel_pdf(x, loc, scale)
# calculates L2
cdf_at_threshold = gumbel_cdf(threshold, loc, scale)
L2 = 1 - cdf_at_threshold
return L1*L2
def gumbel_pdf(x, loc, scale):
"""Returns the value of Gumbel's pdf with parameters loc and scale at x .
"""
# exponent
e = math.exp(1)
# substitute
z = (x - loc)/scale
return (1/scale) * (e**(-(z + (e**(-z)))))
def gumbel_cdf(x, loc, scale):
"""Returns the value of Gumbel's cdf with parameters loc and scale at x.
"""
# exponent
e = math.exp(1)
return (e**(-e**(-(x-loc)/scale)))
最佳答案
首先,优化函数的最简单方法是使用 scipy.optimize是构造目标函数,第一个参数是需要优化的参数列表,后面的参数指定其他内容,例如数据和固定参数。
其次,使用 numpy 提供的矢量化会很有帮助
因此我们有这些:
In [61]:
#modified pdf and cdf
def gumbel_pdf(x, loc, scale):
"""Returns the value of Gumbel's pdf with parameters loc and scale at x .
"""
# substitute
z = (x - loc)/scale
return (1./scale) * (np.exp(-(z + (np.exp(-z)))))
def gumbel_cdf(x, loc, scale):
"""Returns the value of Gumbel's cdf with parameters loc and scale at x.
"""
return np.exp(-np.exp(-(x-loc)/scale))
In [62]:
def trunc_GBL(p, x):
threshold=p[0]
loc=p[1]
scale=p[2]
x1=x[x<threshold]
nx2=len(x[x>=threshold])
L1=(-np.log((gumbel_pdf(x1, loc, scale)/scale))).sum()
L2=(-np.log(1-gumbel_cdf(threshold, loc, scale)))*nx2
#print x1, nx2, L1, L2
return L1+L2
In [63]:
import scipy.optimize as so
In [64]:
#first we make a simple Gumbel fit
so.fmin(lambda p, x: (-np.log(gumbel_pdf(x, p[0], p[1]))).sum(), [0.5,0.5], args=(np.array(non_truncated_data),))
Optimization terminated successfully.
Current function value: 35.401255
Iterations: 70
Function evaluations: 133
Out[64]:
array([ 16.47028986, 0.72449091])
In [65]:
#then we use the result as starting value for your truncated Gumbel fit
so.fmin(trunc_GBL, [17, 16.47028986, 0.72449091], args=(np.array(non_truncated_data),))
Optimization terminated successfully.
Current function value: 0.000000
Iterations: 25
Function evaluations: 94
Out[65]:
array([ 13.41111111, 16.65329308, 0.79694 ])
在 trunc_GBL 中函数我用缩放后的 pdf 替换了你的 pdf
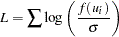
看这里的原理,基本上是因为你的L1是基于 pdf 和 L2基于 cdf:http://support.sas.com/documentation/cdl/en/statug/63033/HTML/default/viewer.htm#statug_lifereg_sect018.htm
然后我们注意到一个问题,请参阅:Current function value: 0.000000在最后的输出中。负对数似然函数为0。
这是因为:
In [66]:
gumbel_cdf(13.41111111, 16.47028986, 0.72449091)
Out[66]:
2.3923515777163676e-30
实际上为 0。这意味着根据您刚才描述的模型,当阈值足够低时总是会达到最大值,这样 L1不存在(x < threshold 为空)和L2是 1(对于数据中的所有项目,1-F(C) 是 1)。
因此,您的模型在我看来不太合适。您可能需要重新考虑一下。
编辑
我们可以进一步隔离threshold并将其视为固定参数:
def trunc_GBL(p, x, threshold):
loc=p[0]
scale=p[1]
x1=x[x<threshold]
nx2=len(x[x>=threshold])
L1=(-np.log((gumbel_pdf(x1, loc, scale)/scale))).sum()
L2=(-np.log(1-gumbel_cdf(threshold, loc, scale)))*nx2
#print x1, nx2, L1, L2
return L1+L2
并以不同的方式调用优化器:
so.fmin(trunc_GBL, [0.5, 0.5], args=(X, np.percentile(X, 20)))
Optimization terminated successfully.
Current function value: 20.412818
Iterations: 72
Function evaluations: 136
Out[9]:
array([ 16.34594943, 0.45253201])
这样,如果您想要 70% 的分位数,只需将其更改为 np.percentile(X, 30)等等。 np.percentile()只是另一种方式做 .quantile(0.8)
关于python - 如何使用 scipy.optimize 查找 gumbel 分布的参数,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/23217484/