编辑:我已经成功了——我忘了放入一个空格作为多条边的分隔符。
我有这个 Python 正则表达式,它可以处理我必须解析的大部分字符串。
edge_value_pattern = re.compile(r'(?P<edge>e[0-9]+) +(?P<label1>[^ ]*)[^"]+"(?P<word>[^"]+)"[^:]+:: (?P<label2>[^\n]+)')
这是我的正则表达式要解析的示例字符串:
'e0 BIKE-EVENT 1 "biking" 2'
它正确存储e0进入edge集团,BIKE-EVENT进入label1组,和 "biking"进入word团体。最后一组,label2 , 用于字符串的稍微不同的变体,如下所示。请注意 label2当给定如下所示的字符串时,正则表达式组的行为符合预期。
'e29 e30 "of" :: of, OF'
然而,正则表达式模式填写label1值为 e30.事实是这个字符串没有任何 label1值--应该是None或者至少是空字符串。一个临时解决方案是解析 label1使用正则表达式来确定它是实际标签还是只是另一条边。我想知道是否有办法修改我原来的正则表达式,以便组 edge全部edges .例如,上述字符串的输出为:
edge = "e29 e30"
label1 = None
word = of
label2 = of, OF
我在下面尝试了这个解决方案,我认为这将转化为简单地遍历第一组,edge (如果我有一个实际的 FSA,这将是微不足道的),但它不会改变正则表达式的行为。
edge_value_pattern = re.compile(r'(?P<edge>(e[0-9]+)+) +(?P<label1>[^ ]*)[^"]+"(?P<word>[^"]+)"[^:]+:: (?P<label2>[^\n]+)')
最佳答案
如果您希望 edge 匹配 "e29 e30",您必须将重复放在组内部,而不是外部。 p>
你通过在 edge 组中插入一个新的组来做到这一点,并重复 + - 这很好,虽然你可能想要一个非捕获组在那里 - 但是你忘了在重复组中包含空格。
(您还保留了外部重复,并使用了一个您可能想要非捕获的捕获组,但这些不太严重。)
只看那个片段:
(?P<edge>(e[0-9]+)+)
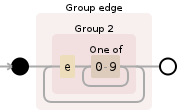
在这里,表达式将 e29 作为一个匹配项,然后将 e30 作为后续匹配项。因此,如果您向表达式添加任何其他内容,它要么会错过 e29,要么就会失败。但是添加空格:
(?P<edge>(e[0-9]+ )+)

现在它匹配 e29 e30 加上尾随空格作为一个匹配项,这意味着您可以添加任何额外的东西并且它会起作用(只要你得到正确的额外东西 - 你仍然需要删除多余的 +,而且我认为您可能需要进行其他一些非贪婪的重复……)。
关于python - 在 Python 正则表达式中循环组,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/27240757/