我正在尝试通过考虑时间戳来创建一个新的 df。具体来说,对于下面的 df,我首先返回所有行,其中 Number 中的 integer 是 diff 来自前一行。
然后我想根据这两条规则调整这些时间戳:
- 如果
Number中的整数增加,将时间戳四舍五入到前 15 分钟标记 - 如果
Number中的整数减少,保持当前时间戳
我不确定这是否是最有效的方法,但我目前正在通过对两个单独的数据帧进行子集化然后合并来进行此操作。我返回所有增加的数字并修改时间戳,同时返回所有减少的数字并保持不变。当我合并这两个时,我就会遇到麻烦。
如果整数差异之间的差距很近,则四舍五入可能会导致序列不正确。本质上,如果整数减少后的 15 分钟内有一个增加的整数,则 Number 是不正确的。因为它是四舍五入的,所以生成的时间戳放错了地方。
df = pd.DataFrame({
'Time' : ['1/1/1900 8:00:00','1/1/1900 9:59:00','1/1/1900 10:10:00','1/1/1900 12:21:00','1/1/1900 12:26:00','1/1/1900 13:00:00','1/1/1900 13:26:00','1/1/1900 13:29:00','1/1/1900 14:20:00','1/1/1900 18:10:00'],
'Number' : [1,1,2,2,3,2,1,2,1,1],
})
# First and last entry in df. This ensures the start/end of the subsequent
# df includes rows where the 'Number' increases/decreases.
first_time = df.loc[0,'Time']
last_time = df.loc[df.index[-1], 'Time']
# Insert 0 prior to first race
df.loc[-1] = [first_time, 0]
df.index = df.index + 1
df.sort_index(inplace=True)
# Insert 0 after the last race
df.loc[len(df)] = last_time, 0
# Convert to datetime. Include new column that rounds all timestamps. If timestamp
# is within 10mins of nearest 15min, round to that point.
df['Time'] = pd.to_datetime(df['Time'])
df['New Time'] = df['Time'].sub(pd.Timedelta(11*60, 's')).dt.floor(freq='15T')
# Create separate df's. Inc contains all increased integers. Dec contains
# all decreases in integers
df = df[df['Number'] != df['Number'].shift()]
Inc = df[df['Number'] > df['Number'].shift()]
Dec = df[df['Number'] < df['Number'].shift()]
del Inc['Time']
del Dec['New Time']
Inc.columns = ['Number','Time']
# Merge df's
df1 = pd.concat([Inc,Dec], sort = True)
# Sort so it's time ordered
df1['Time'] = pd.to_datetime(df1['Time'])
df1 = df1.iloc[pd.to_timedelta(df1['Time']).argsort()]
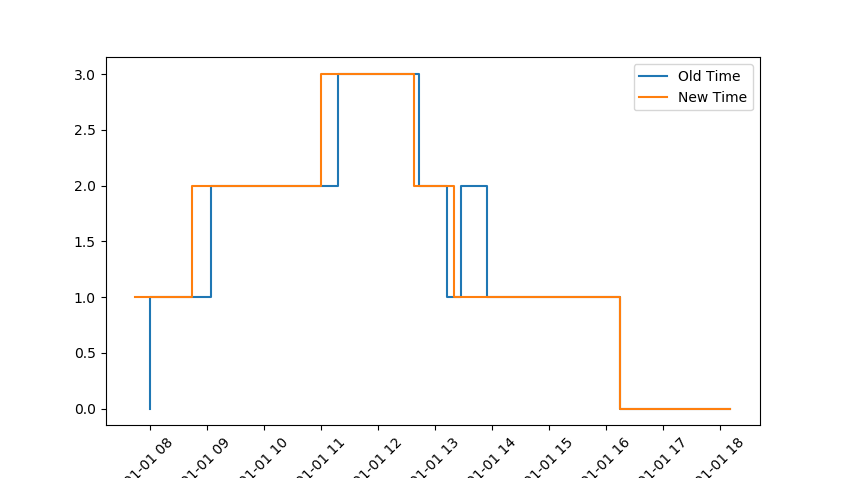
我在下面绘制了一张图来显示当 Number 增加到 2 时图中的 New Time 是如何不记录的1:30:00 因为新的舍入。
我希望发生的事情是,如果整数的减少落在增加的整数的 15 分钟之间,则忽略它。
x = df['Time']
x2 = df1['Time']
y = df['Number']
y2 = df1['Number']
plt.plot(x,y, drawstyle='steps-mid', label = 'Old Time')
plt.plot(x2,y2, drawstyle='steps-mid', label = 'New Time')
plt.legend()
plt.xticks(rotation = 45)
输出:
Number Time
1 1 1900-01-01 07:45:00
3 2 1900-01-01 09:45:00
5 3 1900-01-01 12:15:00
6 2 1900-01-01 13:00:00
8 2 1900-01-01 13:15:00 *Was previously 13:29:00
7 1 1900-01-01 13:26:00 *To be removed because within 15 of previous row
9 1 1900-01-01 14:20:00
11 0 1900-01-01 18:10:00
预期输出:
Number Time
1 1 1900-01-01 07:45:00
3 2 1900-01-01 09:45:00
5 3 1900-01-01 12:15:00
6 2 1900-01-01 13:00:00
8 2 1900-01-01 13:15:00
9 1 1900-01-01 14:20:00
11 0 1900-01-01 18:10:00
编辑 2:
当连续 15 分钟的时间段增加时,我遇到了麻烦。它似乎错过了第一次增加而只返回第二次增加。
df = pd.DataFrame({
'Time' : ['1/1/1900 8:00:00','1/1/1900 9:49:00','1/1/1900 10:00:00','1/1/1900 10:13:00','1/1/1900 12:26:00','1/1/1900 13:00:00','1/1/1900 13:22:00','1/1/1900 13:45:00','1/1/1900 14:21:00','1/1/1900 14:36:00'],
'Number' : [1,2,2,2,1,1,2,2,3,4],
})
# if you Time column is not of type datetime64, please execute the following line:
df['Time']= df['Time'].astype('datetime64')
# add some auxillary columns
df['row_id']= df.index # this is needed for the delete indexer to avoid deleting adjusted rows that are joined with itself
df['increase']= df['Number'] > df['Number'].shift(1).fillna(0) # this is to identify the rows where the value increases and fillna(0) makes sure the value of the first row is regarded as an increase if it is larger than 0
df['Adjusted Time']= df['Time'].where(~df['increase'], df['Time'].sub(pd.Timedelta(11*60, 's')).dt.floor('15min')) # the Adjusted Time is the time we want to display later and also forms a range to delete (we want to delete other records later, if they lie between "Adjusted Time" and "Time"
# merge the ranges to identify the rows, we need to delete
get_delete_ranges= df[df['Time'] > df['Adjusted Time']] # those are the ranges, for which we have to look if there is something else inbetween
df_with_del_ranges= pd.merge_asof(df, get_delete_ranges, left_on='Time', right_on='Adjusted Time', tolerance=pd.Timedelta('15m'), suffixes=['', '_del'])
# create an indexer for the rows to delete
del_row= (df_with_del_ranges['row_id_del'] != df_with_del_ranges['row_id']) & (df_with_del_ranges['Time'] >= df_with_del_ranges['Adjusted Time_del']) & (df_with_del_ranges['Time'] <= df_with_del_ranges['Time_del'])
# delete the rows in the overlapping ranges
df_with_del_ranges.drop(df_with_del_ranges[del_row].index, axis='index', inplace=True)
# remove the auxillary columns and restore the originals column names
df_with_del_ranges.drop([col for col in df_with_del_ranges if col not in ['People', 'Adjusted Time']], axis='columns', inplace=True)
df_with_del_ranges.rename({'Adjusted Time': 'Time'}, axis='columns', inplace=True)
输出:
Number Time
0 1 1900-01-01 07:45:00
1 2 1900-01-01 09:30:00
2 2 1900-01-01 10:00:00
3 2 1900-01-01 10:13:00
4 1 1900-01-01 12:26:00
6 2 1900-01-01 13:00:00
7 2 1900-01-01 13:45:00
9 4 1900-01-01 14:15:00
预期输出:
Number Time
0 1 1900-01-01 07:45:00
1 2 1900-01-01 09:30:00
2 2 1900-01-01 10:00:00
3 2 1900-01-01 10:13:00
4 1 1900-01-01 12:26:00
6 2 1900-01-01 13:00:00
7 2 1900-01-01 13:45:00
8 3 1900-01-01 14:00:00 #Index 8 in df has an increase at 14:21. Should be rounded up to 14:00 and Number should be 3
9 4 1900-01-01 14:15:00
最佳答案
请尝试以下代码:
# if you want the last time in your dataframe to be zero, just execute the following line (as this is equivalent to adding a new column and deleting the old one):
df.iloc[-1, 1]= 0
# if you Time column is not of type datetime64, please execute the following line:
df['Time']= df['Time'].astype('datetime64')
# add some auxillary columns
df['row_id']= df.index # this is needed for the delete indexer to avoid deleting adjusted rows that are joined with itself
df['increase']= df['Number'] > df['Number'].shift(1).fillna(0) # this is to identify the rows where the value increases and fillna(0) makes sure the value of the first row is regarded as an increase if it is larger than 0
df['Adjusted Time']= df['Time'].where(~df['increase'], df['Time'].sub(pd.Timedelta(11*60, 's')).dt.floor('15min')) # the Adjusted Time is the time we want to display later and also forms a range to delete (we want to delete other records later, if they lie between "Adjusted Time" and "Time"
# merge the ranges to identify the rows, we need to delete
get_delete_ranges= df[df['Time'] > df['Adjusted Time']] # those are the ranges, for which we have to look if there is something else inbetween
df_with_del_ranges= pd.merge_asof(df, get_delete_ranges, left_on='Time', right_on='Adjusted Time', tolerance=pd.Timedelta('15m'), suffixes=['', '_del'])
# create an indexer for the rows to delete
del_row= (df_with_del_ranges['row_id_del'] != df_with_del_ranges['row_id']) & (df_with_del_ranges['Time'] >= df_with_del_ranges['Adjusted Time_del']) & (df_with_del_ranges['Time'] <= df_with_del_ranges['Time_del'])
# delete the rows in the overlapping ranges
df_with_del_ranges.drop(df_with_del_ranges[del_row].index, axis='index', inplace=True)
# remove the auxillary columns and restore the originals column names
df_with_del_ranges.drop([col for col in df_with_del_ranges if col not in ['Number', 'Adjusted Time']], axis='columns', inplace=True)
df_with_del_ranges.rename({'Adjusted Time': 'Time'}, axis='columns', inplace=True)
这导致:
In [131]: df_with_del_ranges
Out[131]:
Number Time
0 1 1900-01-01 07:45:00
2 2 1900-01-01 09:45:00
4 3 1900-01-01 12:15:00
5 2 1900-01-01 13:00:00
7 2 1900-01-01 13:15:00
8 1 1900-01-01 14:20:00
9 0 1900-01-01 18:10:00
如果没有 .loc[-1, 1]=0,最后一行的 Number 列将包含 1。
关于python - 子集 df 以针对时间戳进行调整,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/57087260/