我正在尝试用 Python 求解耦合的一阶 ODE 系统。我对此很陌生,但是 Zombie Apocalypse example到目前为止,来自 SciPy.org 的帮助很大。
在我的案例中,一个重要的区别是用于“驱动”我的 ODE 系统的输入数据在不同的时间点突然变化,我不确定如何最好地处理这个问题。下面的代码是我能想到的最简单的例子来说明我的问题。我很欣赏这个例子有一个简单的解析解,但我的实际 ODE 系统更复杂,这就是为什么我试图了解数值方法的基础知识。
简化示例
考虑一个底部有孔的桶(这种“线性水库”是许多水文模型的基本构建 block )。桶的输入流量为R,孔的输出流量为Q。 Q 假定与桶中的水量 V 成正比。比例常数通常写为 ,其中 T 是商店的“停留时间”。这给出了一个简单的 ODE 形式
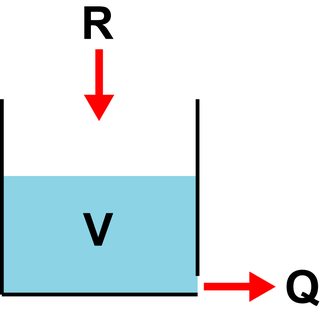
实际上,R 是观察到的每日总降雨量时间序列。 在每一天,假设降雨率是恒定的,但在天之间,降雨率突然变化(即R是一个不连续的 时间的函数)。我试图了解这对求解 ODE 的意义。
策略一
最明显的策略(至少对我而言)是在每个降雨时间步长内分别应用 SciPy 的 odeint 函数。这意味着我可以将 R 视为常数。像这样:
import numpy as np, pandas as pd, matplotlib.pyplot as plt, seaborn as sn
from scipy.integrate import odeint
np.random.seed(seed=17)
def f(y, t, R_t):
""" Function to integrate.
"""
# Unpack parameters
Q_t = y[0]
# ODE to solve
dQ_dt = (R_t - Q_t)/T
return dQ_dt
# #############################################################################
# User input
T = 10 # Time constant (days)
Q0 = 0. # Initial condition for outflow rate (mm/day)
days = 300 # Number of days to simulate
# #############################################################################
# Create a fake daily time series for R
# Generale random values from uniform dist
df = pd.DataFrame({'R':np.random.uniform(low=0, high=5, size=days+20)},
index=range(days+20))
# Smooth with a moving window to make more sensible
df['R'] = pd.rolling_mean(df['R'], window=20)
# Chop off the NoData at the start due to moving window
df = df[20:].reset_index(drop=True)
# List to store results
Q_vals = []
# Vector of initial conditions
y0 = [Q0, ]
# Loop over each day in the R dataset
for step in range(days):
# We want to find the value of Q at the end of this time step
t = [0, 1]
# Get R for this step
R_t = float(df.ix[step])
# Solve the ODEs
soln = odeint(f, y0, t, args=(R_t,))
# Extract flow at end of step from soln
Q = float(soln[1])
# Append result
Q_vals.append(Q)
# Update initial condition for next step
y0 = [Q, ]
# Add results to df
df['Q'] = Q_vals
策略 2
第二种方法涉及简单地将所有内容提供给 odeint 并让它处理不连续性。使用与上述相同的参数和 R 值:
def f(y, t):
""" Function used integrate.
"""
# Unpack incremental values for S and D
Q_t = y[0]
# Get the value for R at this t
idx = df.index.get_loc(t, method='ffill')
R_t = float(df.ix[idx])
# ODE to solve
dQ_dt = (R_t - Q_t)/T
return dQ_dt
# Vector of initial parameter values
y0 = [Q0, ]
# Time grid
t = np.arange(0, days, 1)
# solve the ODEs
soln = odeint(f, y0, t)
# Add result to df
df['Q'] = soln[:, 0]
这两种方法都给出了相同的答案,看起来像这样:

然而,第二种策略虽然在代码方面更紧凑,但它比第一种远慢。我猜这与 R 中的不连续性导致 odeint 出现问题有关?
我的问题
- 策略 1 是这里的最佳方法,还是有更好的方法?
- 策略 2 是个坏主意吗?为什么这么慢?
谢谢!
最佳答案
1.) 是
2.) 是
两者的原因:Runge-Kutta 求解器期望 ODE 函数的可微阶数至少与求解器的阶数一样高。这是必需的,以便存在给出预期误差项的泰勒展开。这意味着即使是 1 阶欧拉方法也需要一个可微分的 ODE 函数。因此不允许跳跃,1 阶可以容忍扭结,但高阶求解器则不能。
对于具有自动步长调整的实现尤其如此。每当接近一个不满足微分阶数的点时,求解器就会看到一个僵硬的系统并将步长推向 0,这会导致求解器变慢。
如果您使用步长固定且步长小于 1 天的求解器,则可以结合策略 1 和 2。然后,当天轮流的采样点作为(隐式)新常量的重启点。
关于python - 求解具有不连续输入/强制数据的 ODE,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/32225472/