我想基于组迭代地将多列中的行值附加到新 DataFrame 中的新列。
我的目标是为每个客户保留 1 行,其中 1 列用于客户 ID,1 列用于其时间线,列出每个事件的日期,后跟事件描述,对于所有日期和事件,按时间顺序排列。
我已经用一系列字典解决了这个问题。我正在寻找一种干净、优雅、pandas 风格的方法来完成此任务,因为此代码将频繁运行,并对客户、事件等进行少量更改。
示例:
import pandas as pd
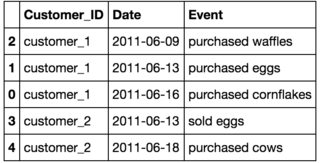
df_have = pd.DataFrame({'Customer_ID':['customer_1','customer_1','customer_1','customer_2','customer_2'],
'Event':['purchased cornflakes','purchased eggs', 'purchased waffles','sold eggs','purchased cows'],
'Date':['2011-06-16','2011-06-13','2011-06-09','2011-06-13','2011-06-18']})
df_have['Date'] = pd.to_datetime(df_have['Date'])
df_have.sort_values(['Customer_ID','Date'], inplace =True)
df_have
df_want = pd.DataFrame({'Customer_ID':['customer_1','customer_2'],
'Time_Line':[['2011-06-09,purchased waffles,2011-06-13,purchased eggs,2011-06-16,purchased cornflakes'],
['2011-06-13,sold eggs,2011-06-18,purchased cows']]})
df_want

最佳答案
步骤:
1) 将 Customer_ID 设置为索引轴,因为它将在整个操作过程中保持静态。
2) stack 使得 Date 和 Event 相互重叠.
3) 对索引执行 groupby (level=0) 并将唯一的列转换为 list。由于我们已按此顺序堆叠它们,因此它们会交替出现。
# set maximum width of columns to be displayed
pd.set_option('max_colwidth', 100)
df_have.set_index('Customer_ID').stack(
).groupby(level=0).apply(list).reset_index(name="Time_Line")

要更改列表中序列出现的顺序:
df_have.set_index('Customer_ID').reindex_axis(['Event', 'Date'], axis=1).stack(
).groupby(level=0).apply(list).reset_index(name="Time_Line")

关于python - Pandas 迭代地追加来自多个 DataFrame 列的行值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41986081/