我有一个包含待售汽车的 Pandas Dataframe,我想获得每个品牌最受欢迎的汽车,但我似乎无法做到这一点。
我有一个 pandas 数据框,其中包含一些列(例如:车辆类型、价格、里程、年份、品牌、型号等),对于每个汽车品牌,我想检查哪种型号出现最多。
我尝试使用 groupby,如下所示:
popular_models = dataset.groupby('brand').model.value_counts().groupby(level=0).nlargest(1)
但它返回一个 Pandas Series,其中我想要的一些数据存储在索引中,并且它还添加了一个对我来说没有任何意义的重复列。
我想要一个包含 3 列的 DataFrame,如下所示:
(/image/WXw4b.jpg)
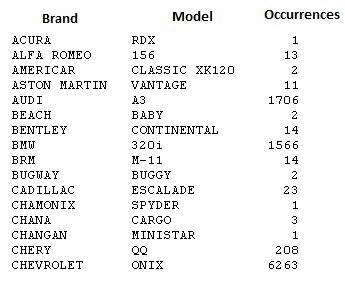{kind=link}
但是,我得到了这样的 pandas 系列:
(/image/2iviA.jpg)
{kind=link}
有人可以帮我解决这个问题吗?
最佳答案
您必须对要保留的两个对象进行分组,然后对要查找出现次数的对象进行计数。这是示例输入文件:
Brand Model
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Acura RDX
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
Beach Baby
BMW 320i
BMW 320i
BMW 320i
BMW 320i
BMW 320i
BMW 320i
BMW 320i
BMW 550i
BMW 550i
BMW 550i
BMW 550i
BMW 550i
BMW 550i
BMW 550i
Cadillac Escalade
Cadillac Escalade
Cadillac Escalade
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
Chana Cargo
简单的 Pandas 单行:
df = pd.read_table('fun.txt', header=0)
print(df.groupby(['Brand','Model'])['Model'].agg(['count']))
输出:
count
Brand Model
Acura RDX 10
BMW 320i 7
550i 7
Beach Baby 10
Cadillac Escalade 3
Chana Cargo 12
如果您想按频率对值进行排序(从大到小)并仅保留最大的一行,请将一行更改为:
groupby_df = (df.groupby(['Brand','Model'])['Model'].agg(['count']).sort_values(by='count', ascending=False).reset_index().drop_duplicates('Brand', keep='first'))
获取:
Brand Model count
0 Chana Cargo 12
1 Acura RDX 10
2 Beach Baby 10
3 BMW 320i 7
5 Cadillac Escalade 3
关于python - 如何获得 pandas 组中最受欢迎的项目?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/54204653/