示例文本:
1. There are 500 employees in our organisation.
2. Abbott employed approximately 103,000 people as of December 31, 2018
3. We currently employ approximately 1,750 employees
4. As of December 31, 2018, we had approximately 25,300 full-time employees.
现在我想在“employe”这个词之前或之后找到最接近的数字。
c = re.search(r'(\w+\s+){0,3}employe(\w+\s+){0,3}', text, re.IGNORECASE)
print(c.group(0))
预期结果:
1. 500
2. 103,000
3. 1,750
4. 25,300
通过上面的代码,我试图找到最近的单词,然后找到其中的数字。
有没有更好的方法呢?
最佳答案
也许,一些类似的表达:
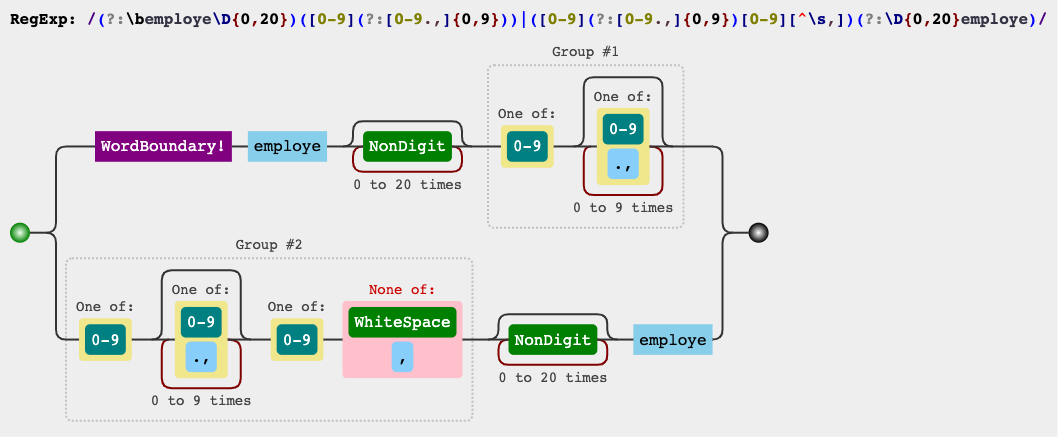
(?:\bemploye\D{0,20})([0-9][0-9,]*)[^.,]|([0-9][0-9,]*)[^.,](?:\D{0,20}employe)
也可能在某种程度上进行一些修改。
Demo
测试
import re
expression = r"(?i)(?:\bemploye\D{0,20})([0-9][0-9,]*)[^.,]|([0-9][0-9,]*)[^.,](?:\D{0,20}employe)"
string = """
1. There are 500 employees in our organisation.
2. Abbott employed approximately 103,000 people as of December 31, 2018
3. We currently employ approximately 1,750 employees
4. As of December 31, 2018, we had approximately 25,300 full-time employees.
5. As of December 31, 2018, we had approximately 30 full-time employees.
6. As of December 31, 2018, we had approximately 3 full-time employees.
"""
print(re.findall(expression, string))
输出
[('', '500'), ('103,000', ''), ('', '1,750'), ('', '25,300'), ('', '30'), ('', '3')]
如果您想简化/修改/探索表达式,在regex101.com 的右上面板中已对此进行了解释.如果你愿意,也可以在this link观看。 ,它将如何与一些样本输入相匹配。
正则表达式电路
jex.im可视化正则表达式:
关于python - 如何在python中的特定文本之前或之后找到最近的数字,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/57945858/