我有两个时间序列。每个时间序列(s1 和 s2)都由一个值列表和一个相应的时间列表(例如时间戳或其他)表示。我正在使用 python,所以例如我有:
s1_values = [6,8,6,3,7,9] # len(s1_values) == len(s1_times)
s1_times = [1,3,6,7,8,12]
s2_values = [3,8,7,2,5,4,6,2] # len(s2_values) == len(s2_times)
s2_times = [2,4,5,7,8,9,10,13]
我希望看到两个时间序列 s1 和 s2 之间的关系,所以我希望能够使用 Matplotlib 绘制 s1_values(在 x 轴上)与 s2_values(在 y 轴上)的关系,但是由于这两个时间序列没有及时对齐,我不知道该怎么做。
也许有一些针对时间序列执行此操作的常用方法,但我不知道它们。
最佳答案
您可以使用 pandas ( docs ),它非常适合时间序列数据。在这种情况下,您将制作两个数据框,然后合并并对它们进行排序。
merge 为您提供了一个合并的“时间”系列(很多不同的合并方式 here ),将 nan 值插入到值列中那个时候的值(value)。然后按共享的 Time 列对其进行排序。 df.fillna 函数 ( docs ) 接受 method 参数,如果它是 ffill 或 pad 则填充与最后一个有效值的差距,如果 bfill 填充下一个有效值。或者,您可以使用 df.interpolate 对缺失值进行线性插值 (docs)。
方便的是 pandas 包装了 matplotlib,因此您可以直接从数据帧中绘图。
import matplotlib.pyplot as plt
import pandas as pd
s1_values = [6,8,6,3,7,9]
s1_times = [1,3,6,7,8,12]
s2_values = [3,8,7,2,5,4,6,2]
s2_times = [2,4,5,7,8,9,10,13]
df1 = pd.DataFrame(zip(s1_times, s1_values), columns=['Time', 's1 values'])
df2 = pd.DataFrame(zip(s2_times, s2_values), columns=['Time', 's2 values'])
df = df1.merge(df2, how='outer', on='Time', sort='Time')
df.fillna(method='pad', inplace=True) # or df.interpolate(inplace=True)
df.plot(kind='scatter', x='s1 values', y='s2 values')
plt.show()
使用fillna(method='ffill')

使用interpolate()
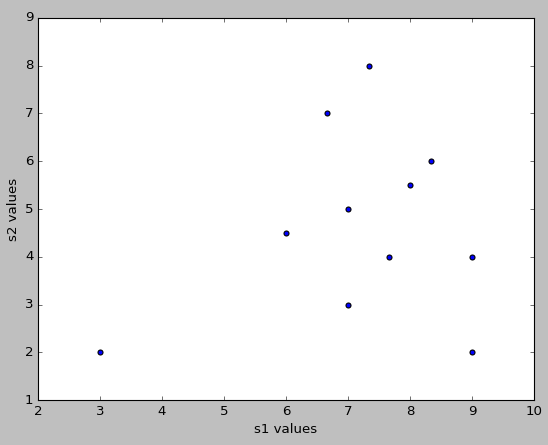
关于python - 绘制具有不同日期的两个时间序列的值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/36531939/