这个问题不重复,因为将用户代理添加到 header 并不能解决任何问题。
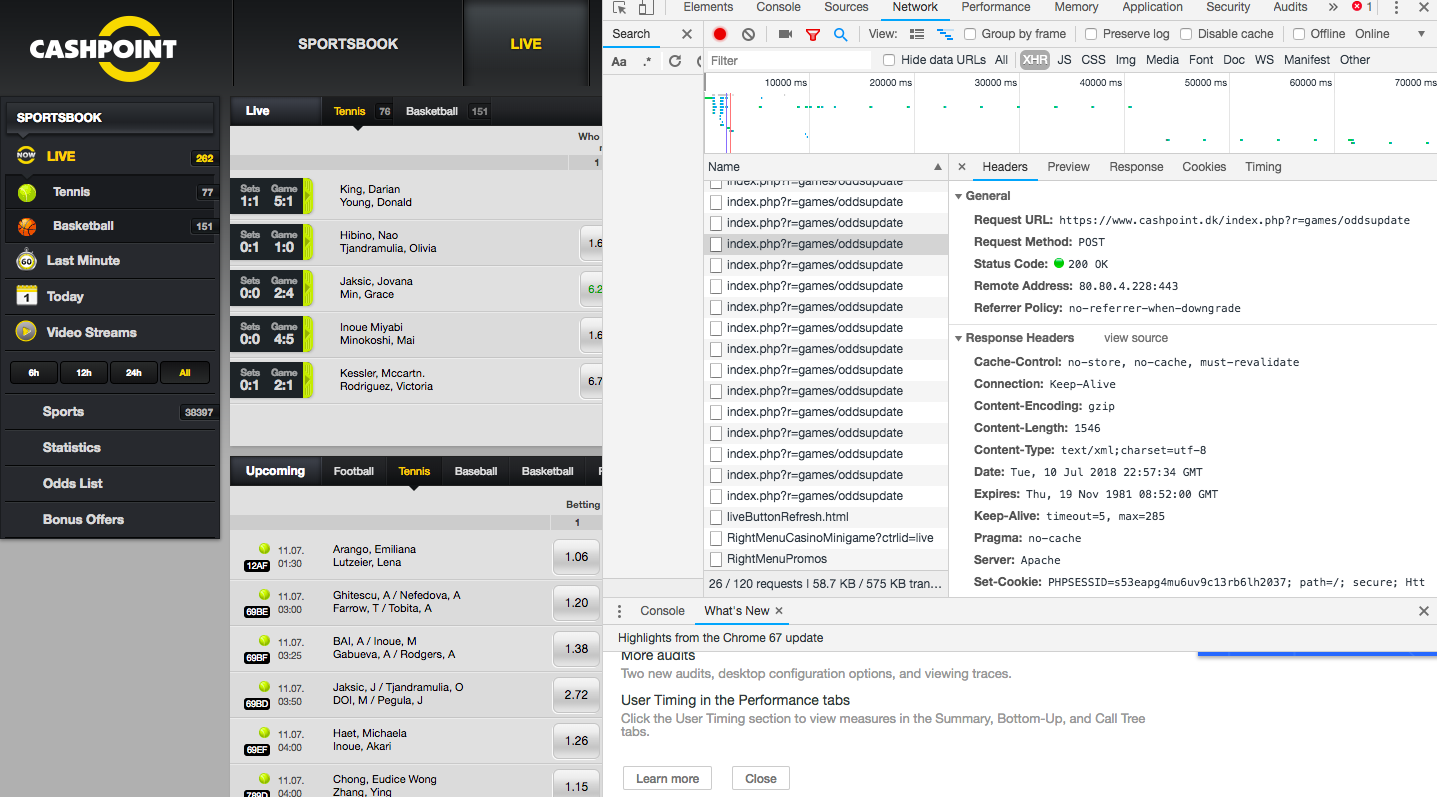
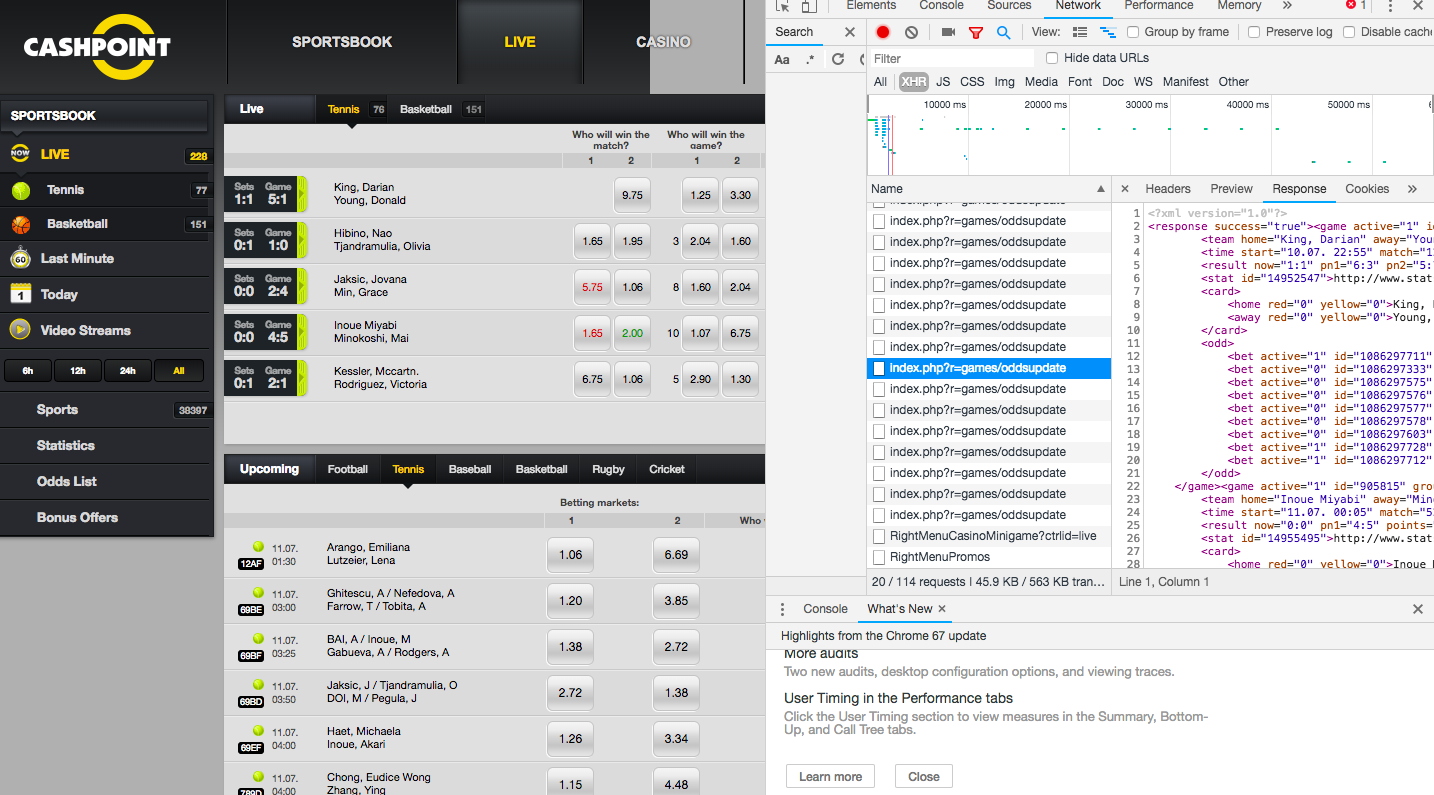
我一直在尝试从此 URL 获得回复。它是 XML 提要,而不是 HTML 文件。这是来自 cashpoint.com 的 live soccer page 每秒更新的实时动态。 。我可以从最后提到的页面中很好地获取 HTML 页面,但从第一个提到的 URL 中我无法检索 XML 数据。我可以用谷歌浏览器检查器检查它并看到响应就好。但它返回 b''。尝试了获取和发布。
编辑:尝试添加更多标题,但仍然不起作用。
如果检查员可以看到该信息,难道不应该检索到它吗?
下面是我的代码和一些图片(如果您太忙而无法检查链接)。
import requests
class GetFeed():
def __init__(self):
pass
def live_odds(self):
live_index_page = 'https://www.cashpoint.dk/en/live/index.html'
live_oddsupdate = 'https://www.cashpoint.dk/index.php?r=games/oddsupdate'
r = requests.get(live_oddsupdate)
print(r.text)
feed = GetFeed()
feed.live_odds()
最佳答案
首先,在 Chrome 控制台中,您可以看到这是一个 POST 请求,而且您似乎正在 Python 代码中执行 GET 请求。
关于python - 如何根据 google chrome 检查器提供的信息发出 xml http post 请求,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/51275134/