我有一个如下所示的数据框
df = pd.DataFrame({
'subject_id':[1,1,1,1,1,1,1,2,2,2,2,2],
'time_1' :['2173-04-03 12:35:00','2173-04-03 12:50:00','2173-04-05 12:59:00','2173-05-04 13:14:00','2173-05-05 13:37:00','2173-07-03 13:39:00','2173-07-04 11:30:00','2173-04-04 16:00:00','2173-04-09 22:00:00','2173-04-11 04:00:00','2173- 04-13 04:30:00','2173-04-14 08:00:00'],
'val' :[5,5,5,5,1,6,5,5,8,3,4,6]})
df['time_1'] = pd.to_datetime(df['time_1'])
df['day'] = df['time_1'].dt.day
df['month'] = df['time_1'].dt.month
我想要做的是删除不超过 4 或更多 唯一天数的记录/主题
如果您查看我的示例数据框,您会发现 subject_id = 1 只有 3 个唯一日期,即 3,4 和 5,因此我想删除 subject_id = 1 完全。但如果您看到 subject_id = 2,他有 4 个以上的唯一日期,例如 4,9,11,13,14。请注意,日期值具有时间戳,因此我从每个日期时间字段中提取日期并检查唯一记录。
这是我尝试过的
df.groupby(['subject_id','day']).transform('size')>4 # doesn't work
df[df.groupby(['subject_id','day'])['subject_id'].transform('size')>=4] # doesn't produce expected output
我希望我的输出是这样的
最佳答案
将函数从 size 更改为 DataFrameGroupBy.nunique ,仅按 subject_id 列分组:
df = df[df.groupby('subject_id')['day'].transform('nunique')>=4]
或者您也可以使用 filtration ,但是如果您使用更大的数据框或许多独特的组,这应该会更慢:
df = df.groupby('subject_id').filter(lambda x: x['day'].nunique()>=4)
print (df)
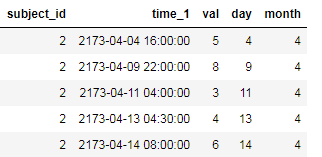
subject_id time_1 val day month
7 2 2173-04-04 16:00:00 5 4 4
8 2 2173-04-09 22:00:00 8 9 4
9 2 2173-04-11 04:00:00 3 11 4
10 2 2173-04-13 04:30:00 4 13 4
11 2 2173-04-14 08:00:00 6 14 4
关于python - 如何使用 pandas 根据唯一天数删除记录?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/58777049/