我发布这个问题是因为许多开发人员以不同的形式或多或少地提出了相同的问题。我自己来回答这个问题(我是iText Group的创始人/CTO),所以它可以是一个“维基答案”。如果 Stack Overflow 的“文档”功能仍然存在,那么这将是文档主题的一个很好的候选者。
源文件:
我正在尝试将以下 HTML 文件转换为 PDF:
<html>
<head>
<title>Colossal (movie)</title>
<style>
.poster { width: 120px;float: right; }
.director { font-style: italic; }
.description { font-family: serif; }
.imdb { font-size: 0.8em; }
a { color: red; }
</style>
</head>
<body>
<img src="img/colossal.jpg" class="poster" />
<h1>Colossal (2016)</h1>
<div class="director">Directed by Nacho Vigalondo</div>
<div class="description">Gloria is an out-of-work party girl
forced to leave her life in New York City, and move back home.
When reports surface that a giant creature is destroying Seoul,
she gradually comes to the realization that she is somehow connected
to this phenomenon.
</div>
<div class="imdb">Read more about this movie on
<a href="www.imdb.com/title/tt4680182">IMDB</a>
</div>
</body>
</html>
在浏览器中,此 HTML 如下所示:

我遇到的问题:
HTMLWorker 根本不考虑 CSS
当我使用
HTMLWorker ,我需要创建一个 ImageProvider以避免出现错误,提示我无法找到图像。我还需要创建一个 StyleSheet更改一些样式的实例:public static class MyImageFactory implements ImageProvider {
public Image getImage(String src, Map<String, String> h,
ChainedProperties cprops, DocListener doc) {
try {
return Image.getInstance(
String.format("resources/html/img/%s",
src.substring(src.lastIndexOf("/") + 1)));
} catch (DocumentException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
public static void main(String[] args) throws IOException, DocumentException {
Document document = new Document();
PdfWriter.getInstance(document, new FileOutputStream("results/htmlworker.pdf"));
document.open();
StyleSheet styles = new StyleSheet();
styles.loadStyle("imdb", "size", "-3");
HTMLWorker htmlWorker = new HTMLWorker(document, null, styles);
HashMap<String,Object> providers = new HashMap<String, Object>();
providers.put(HTMLWorker.IMG_PROVIDER, new MyImageFactory());
htmlWorker.setProviders(providers);
htmlWorker.parse(new FileReader("resources/html/sample.html"));
document.close();
}
结果如下所示:

出于某种原因,
HTMLWorker还显示了<title>的内容标签。我不知道如何避免这种情况。标题中的 CSS 根本没有被解析,我必须在我的代码中定义所有样式,使用 StyleSheet目的。当我查看我的代码时,我发现我使用的很多对象和方法都被弃用了:

所以我决定升级到使用 XML Worker。
使用 XML Worker 时找不到图像
我尝试了以下代码:
public static final String DEST = "results/xmlworker1.pdf";
public static final String HTML = "resources/html/sample.html";
public void createPdf(String file) throws IOException, DocumentException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
document.open();
XMLWorkerHelper.getInstance().parseXHtml(writer, document,
new FileInputStream(HTML));
document.close();
}
这导致了以下 PDF:
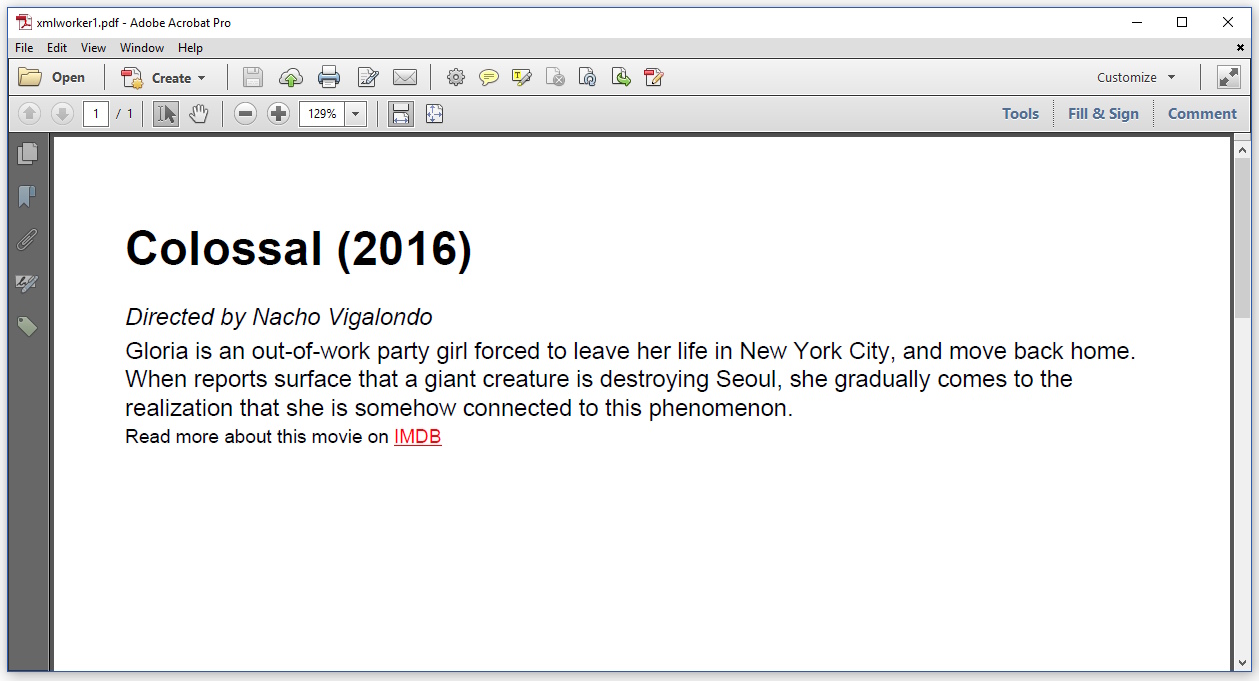
使用默认字体 Helvetica 代替 Times-Roman;这是 iText 的典型特征(我应该在我的 HTML 中明确定义一种字体)。否则,CSS 似乎受到尊重,但图像丢失,我没有收到错误消息。
与
HTMLWorker ,抛出异常,我能够通过引入 ImageProvider 来解决问题。 .让我们看看这是否适用于 XML Worker。XML Worker 并非支持所有 CSS 样式
我像这样修改了我的代码:
public static final String DEST = "results/xmlworker2.pdf";
public static final String HTML = "resources/html/sample.html";
public static final String IMG_PATH = "resources/html/";
public void createPdf(String file) throws IOException, DocumentException {
Document document = new Document();
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(file));
document.open();
CSSResolver cssResolver =
XMLWorkerHelper.getInstance().getDefaultCssResolver(true);
HtmlPipelineContext htmlContext = new HtmlPipelineContext(null);
htmlContext.setTagFactory(Tags.getHtmlTagProcessorFactory());
htmlContext.setImageProvider(new AbstractImageProvider() {
public String getImageRootPath() {
return IMG_PATH;
}
});
PdfWriterPipeline pdf = new PdfWriterPipeline(document, writer);
HtmlPipeline html = new HtmlPipeline(htmlContext, pdf);
CssResolverPipeline css = new CssResolverPipeline(cssResolver, html);
XMLWorker worker = new XMLWorker(css, true);
XMLParser p = new XMLParser(worker);
p.parse(new FileInputStream(HTML));
document.close();
}
我的代码要长得多,但现在图像已呈现:
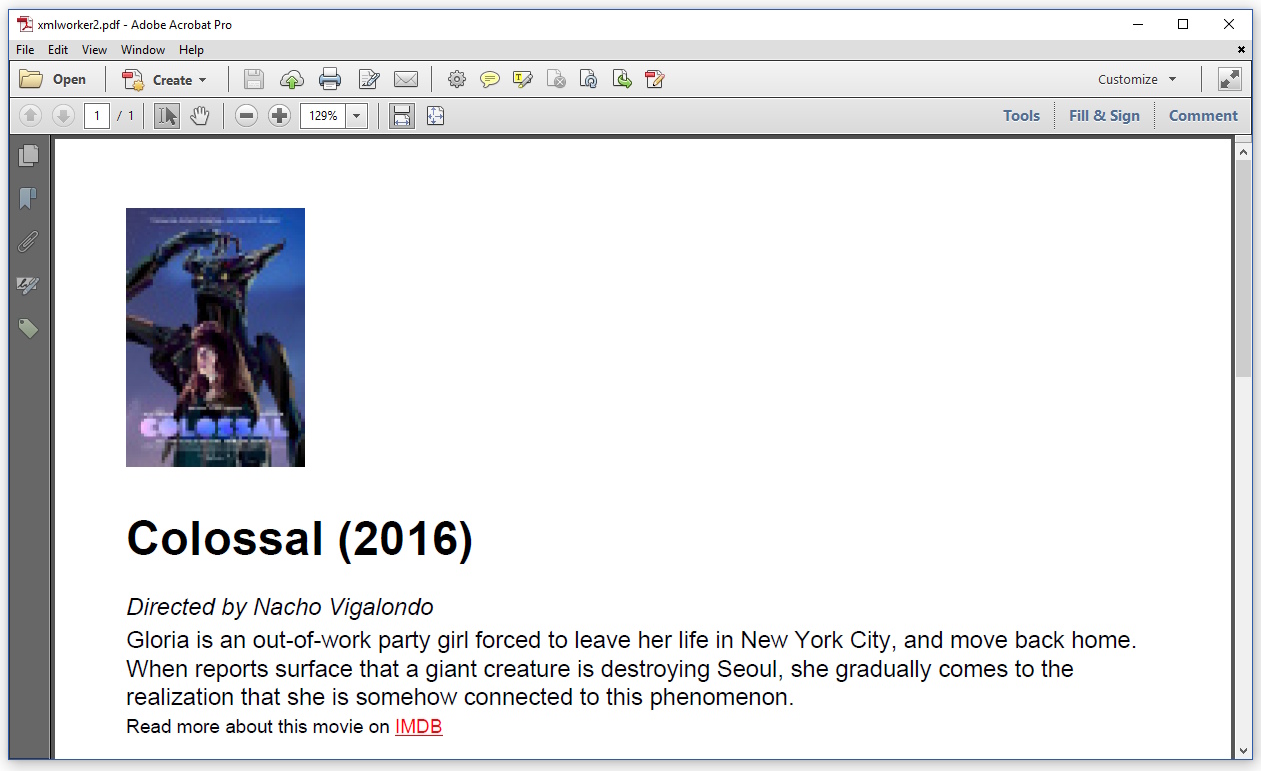
图像比我使用
HTMLWorker 渲染时大这告诉我 CSS 属性 width为 poster类被考虑在内,但 float属性被忽略。我该如何解决?剩下的问题:
所以问题归结为:我有一个特定的 HTML 文件,我尝试将其转换为 PDF。我经历了很多工作,一个接一个地解决问题,但有一个具体问题我无法解决:如何让 iText 尊重定义元素位置的 CSS,例如
float: right ?补充问题:
当我的 HTML 包含表单元素(例如
<input> )时,这些表单元素将被忽略。
最佳答案
为什么你的代码不起作用
如 HTML to PDF tutorial 的介绍中所述, HTMLWorker多年前已被弃用。它不是为了转换完整的 HTML 页面。它不知道 HTML 页面有 <head>和一个 <body>部分;它只是解析所有内容。它旨在解析小的 HTML 片段,您可以使用 StyleSheet 定义样式。类(class);不支持真正的 CSS。
然后是 XML Worker。 XML Worker 旨在作为解析 XML 的通用框架。作为概念证明,我们决定编写一些 XHTML 到 PDF 的功能,但我们并不支持所有的 HTML 标签。例如:根本不支持表单,并且很难支持用于定位内容的 CSS。 HTML 中的表单与 PDF 中的表单非常不同。 iText 架构与 HTML + CSS 架构之间也存在不匹配。渐渐地,我们扩展了 XML Worker,主要是基于客户的请求,但 XML Worker 变成了一个有很多触角的怪物。
最终,我们决定从头开始重写 iText,考虑到 HTML + CSS 转换的要求。这导致 iText 7 .在 iText 7 之上,我们创建了几个附加组件,在此上下文中最重要的一个是 pdfHTML .
如何解决问题
使用最新版本的 iText (iText 7.1.0 + pdfHTML 2.0.0) 将 HTML 从问题转换为 PDF 的代码简化为以下代码段:
public static final String SRC = "src/main/resources/html/sample.html";
public static final String DEST = "target/results/sample.pdf";
public void createPdf(String src, String dest) throws IOException {
HtmlConverter.convertToPdf(new File(src), new File(dest));
}
结果如下所示:

如您所见,这几乎是您所期望的结果。从 iText 7.1.0/pdfHTML 2.0.0 开始,默认字体是 Times-Roman。 CSS 正在受到尊重:图像现在 float 在右侧。
一些额外的想法。
当我提出升级到 iText 7/pdfHTML 2 的建议时,开发人员通常会反对升级到更新的 iText 版本。 请允许我回答我听到的前 3 个论点:
我需要使用免费的 iText,而 iText 7 不是免费的/pdfHTML 插件是封闭源代码。
iText 7 是使用 AGPL 发布的,就像 iText 5 和 XML Worker 一样。 AGPL 允许在开源项目的上下文中免费使用。如果您分发的是封闭源代码/专有产品(例如,您在 SaaS 环境中使用 iText),则不能免费使用 iText;在这种情况下,您必须购买商业许可证。这对于 iText 5 来说已经是正确的; iText 7 仍然如此。至于 iText 5 之前的版本:you shouldn't use these at all .关于 pdfHTML:第一个版本确实只能作为闭源软件使用。我们在 iText Group 内部进行了激烈的讨论:一方面,有些人希望避免公司的大规模滥用,这些公司不听开发人员的意见,因为这些开发人员告诉他们开源不是和免费一样。开发人员告诉我们,他们的老板强制他们做错事,他们无法说服他们的老板购买商业许可证。另一方面,有些人认为我们不应该因为他们老板的错误行为而惩罚他们。最终,赞成开源 pdfHTML 的人,即 iText 的开发人员赢得了争论。请证明他们没有错,并正确使用 iText:如果您免费使用 iText,请尊重 AGPL;如果您在封闭源环境中使用 iText,请确保您的老板购买了商业许可证。
我需要维护一个遗留系统,我必须使用旧的 iText 版本。
严重地?维护还包括应用升级和迁移到您正在使用的软件的新版本。如您所见,使用 iText 7 和 pdfHTML 时所需的代码非常简单,而且比以前所需的代码更不容易出错。迁移项目不应花费太长时间。
我才刚刚开始,我不知道 iText 7;我是在完成我的项目后才发现的。
这就是我发布这个问题和答案的原因。把自己想象成一个极限程序员。扔掉所有代码,重新开始。您会注意到它的工作量没有您想象的那么多,而且您会睡得更好,因为 iText 5 正在逐步淘汰,因为您已经使您的项目面向 future 。我们仍然为付费客户提供支持,但最终,我们将完全停止支持 iText 5。
关于java - 使用 iText 将 HTML 转换为 PDF,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/47895935/