我通读了这个页面:http://neuralnetworksanddeeplearning.com/chap1.html更好地理解神经网络的工作原理。我想用 Java 创建一个没有反向传播或训练的简单前馈网络。
我不清楚的是网络中一层的每个“神经元”所涉及的数学。假设我有三层。第一层采用大小为 100 的输入 vector 。这是否意味着我的第一层将有 100 个神经元?这是否也意味着每个神经元的输入将是所有 100 个输入乘以权重的总和?这是我神经元激活函数的输入总和吗?
在本章中提到,神经元/感知器的所有输入的总和可以重新表示为输入 (x) 和权重 (w) 的点积。我可以将它们视为两个单独的 vector ,它们的点积为我 x1w1 x2w2 x3w3 .. 等等,但是 x1w1 + x2w2 + .. 的总和如何仍然等于点积?
最后,如果一个层应该有 100 个输入和 1000 个输出,这是否意味着该层实际上有 1000 个神经元并且每个神经元有 100 个输入?那么该层每个神经元输出 1 个值,从而给出 1000 个输出?
如果这些问题完全不正确或微不足道,我提前道歉,我已经在网上阅读了一些文档,这是我目前的理解,但是如果不问真正了解它的人就很难验证。如果您有其他资源或视频可以提供帮助,我们将不胜感激。
最佳答案
这是我在 stackOverflow 中的第一个答案,所以请放轻松。
如果我没理解你的问题,你想知道人工神经元背后的数学是如何工作的。神经元由以下列表中显示的 5 个组件组成。 (下标i表示第i个输入或权重。)
- 一组输入,xi。
- 一组权重,wi。
- 一个阈值,u。
- 激活函数 f。
- 单个神经元输出,y。
人工神经元的结构相当简单。
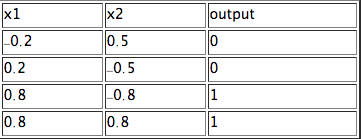
使用单位阶跃激活函数,您可以确定一组将产生以下分类的权重(和阈值): Click to view classification
{kind=link}
看数字 4。激活函数 f。许多不同的功能可以发生,身份功能是最简单的。
神经元输出 Y,是将激活函数应用于输入的加权和的结果,减去阈值。
根据所使用的激活函数,该值可以是离散值或实数。
Here's具有特定函数 F 的 Y 的输出。
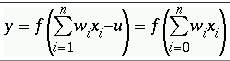{kind=link}
一旦计算出输出,就可以将其传递给另一个神经元(或一组神经元)或由外部环境采样。神经元输出的解释取决于所考虑的问题
@西弗尔
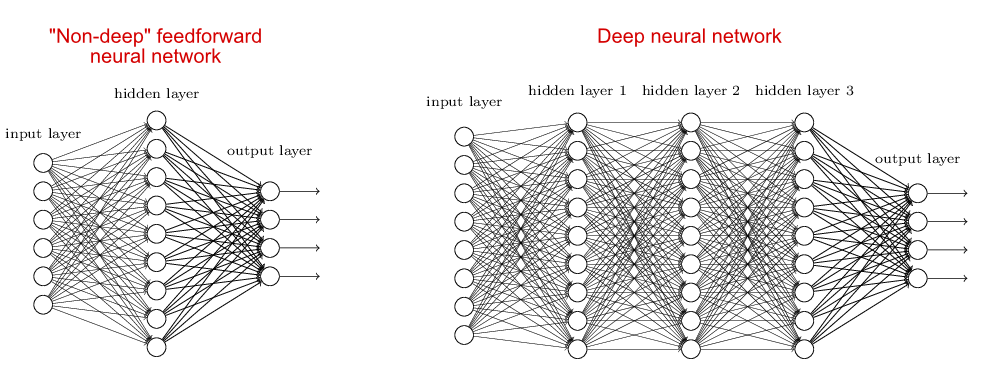
原则上,人工神经网络中可以使用的隐藏层数没有限制。可以使用“堆叠”或深度学习文献中的其他技术来训练此类网络。是的,你可以有 1000 个层,但我不知道你是否会得到很多好处:在深度学习中,我更经常看到 1-20 个隐藏层之间的某处,而不是 1000 个隐藏层。在实践中,层数基于实际考虑,例如,在合理的训练时间和不过度拟合的情况下,什么会导致良好的准确性。
您的问题: 我假设你的意思是说 100 个输入和 1000 个输出? 当一个输入接受加权值时,它的输出将它提供给下一层中的所有其他节点(神经元),但该值仍然来自给定节点。
有许多关于 Java 的“希望清洗”书籍,但如果您真的想进入它,请阅读 This
关于java - 了解神经网络层、节点和点积,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40413247/