我目前在具有 HDP 2.5 的主服务器中运行最新的 zeppelin 源代码,我还有一个工作服务器。
在主服务器下,我检测到在过去 12 天内生成了多个 JAVA 进程,这些进程没有完成并且正在消耗内存。在某一时刻,内存已满,无法在其 Yarn 队列下运行 Zeppelin。我在 Yarn 中有一个队列系统,一个用于 JobServer,另一个用于 Zeppelin。 Zeppelin 目前正在使用 root 运行,但将更改为每个自己的服务帐户。系统是CENTOS 7.2
日志显示了以下进程,为了便于阅读我开始区分它们: 进程1到3好像是zeppelin,我不知道进程4和5是什么。 这里的问题是:是否存在配置问题?为什么 zeppelin-daemon 不杀死这个 JAVA 进程?有什么办法可以避免这个问题?
<p><strong>PROCESS #1</strong>
/usr/java/default/bin/java
-Dhdp.version=2.4.2.0-258
-cp /usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes/
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
:/usr/hdp/current/spark-thriftserver/conf/:/usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-api-jdo-3.2.6.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-core-3.2.10.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-rdbms-3.2.9.jar
:/etc/hadoop/conf/
-Xms1g
-Xmx1g
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log org.apache.spark.deploy.SparkSubmit --conf spark.driver.extraClassPath=::/usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
--conf spark.driver.extraJavaOptions=
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log
--class org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer
/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar 44001
</p><p><strong>PROCESS #2 </strong>
/usr/java/default/bin/java -Dhdp.version=2.4.2.0-258
-cp /usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes/
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
:/usr/hdp/current/spark-thriftserver/conf/
:/usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-api-jdo-3.2.6.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-core-3.2.10.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-rdbms-3.2.9.jar
:/etc/hadoop/conf/
-Xms1g
-Xmx1g
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log
org.apache.spark.deploy.SparkSubmit
--conf spark.driver.extraClassPath=
:
:/usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
--conf spark.driver.extraJavaOptions=
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log
--class org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer
/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
40641
</p><p><strong>PROCESS #3</strong>
/usr/java/default/bin/java
-Dhdp.version=2.4.2.0-258
-cp /usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes/
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
:/usr/hdp/current/spark-thriftserver/conf/
:/usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-api-jdo-3.2.6.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-core-3.2.10.jar
:/usr/hdp/2.4.2.0-258/spark/lib/datanucleus-rdbms-3.2.9.jar
:/etc/hadoop/conf/
-Xms1g
-Xmx1g
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log
org.apache.spark.deploy.SparkSubmit
--conf spark.driver.extraClassPath=::/usr/hdp/2.4.2.0-258/zeppelin/local-repo/2BXMTZ239/*
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar
--conf spark.driver.extraJavaOptions=
-Dfile.encoding=UTF-8 -Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-spark-root-cool-server-name1.log
--class org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer /usr/hdp/2.4.2.0-258/zeppelin/interpreter/spark/zeppelin-spark_2.10-0.7.0-SNAPSHOT.jar 60887
</p><p><strong>PROCESS #4</strong>
/usr/java/default/bin/java
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-cassandra-root-cool-server-name1.log
-Xms1024m
-Xmx1024m
-XX:MaxPermSize=512m
-cp ::/usr/hdp/2.4.2.0-258/zeppelin/interpreter/cassandra/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
:
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer
</p><p><strong>PROCESS #5</strong>
/usr/java/default/bin/java
-Dfile.encoding=UTF-8
-Dlog4j.configuration=file:///usr/hdp/2.4.2.0-258/zeppelin/conf/log4j.properties
-Dzeppelin.log.file=/var/log/zeppelin/zeppelin-interpreter-cassandra-root-cool-server-name1.log
-Xms1024m -Xmx1024m -XX:MaxPermSize=512m
-cp ::/usr/hdp/2.4.2.0-258/zeppelin/interpreter/cassandra/*
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/lib/*
::/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-interpreter/target/test-classes
:/usr/hdp/2.4.2.0-258/zeppelin/zeppelin-zengine/target/test-classes org.apache.zeppelin.interpreter.remote.RemoteInterpreterServer </p>最佳答案
Apache Zeppelin 使用 multi-process architecture ,其中每个解释器至少作为一个单独的 JVM 进程运行,通过 Apache Thrift 协议(protocol)与 ZeppelinServer 进行通信。
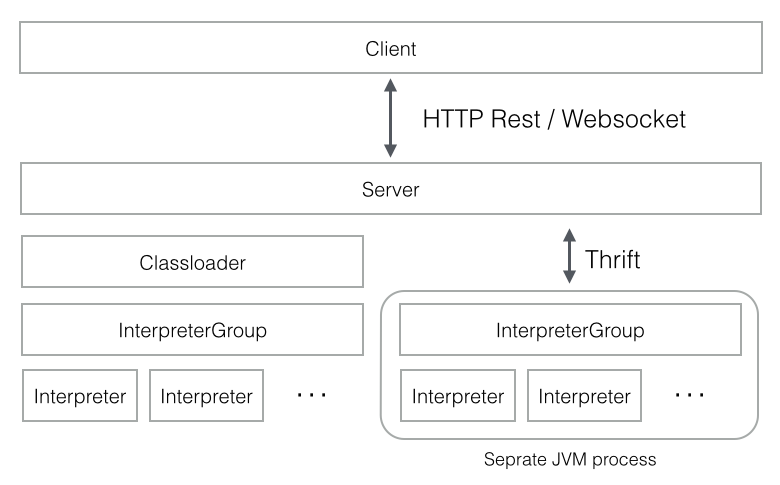
您的情况中的 4 和 5 看起来像 Cassandra 解释器进程。
您可以随时从 Interpreters 菜单中的 Zeppelin UI 关闭/重新启动它们。要了解有关此功能以及其他解释器相关功能的更多信息,请访问 Zeppelin official docs
关于java - Zeppelin 占用多个 JAVA 进程,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40739522/