我有一个程序可以解析大约 50MB 的 XML 文件并将数据提取到内部对象结构中,而没有指向原始 XML 文件的链接。当我尝试粗略估计我需要多少内存时,我估计是 40MB。
但是我的程序需要大约 350MB,我试图找出会发生什么。我使用 boost::shared_ptr,所以我没有处理原始指针,希望我没有产生内存泄漏。
我试着写下我所做的,我希望有人能指出我过程中的问题,错误的假设等等。
首先,我是如何衡量的?我使用 htop 发现我的内存已满,并且使用我的代码段的进程正在使用大部分内存。为了总结不同线程的内存并获得更漂亮的输出,我使用了 http://www.pixelbeat.org/scripts/ps_mem.py这证实了我的观察。
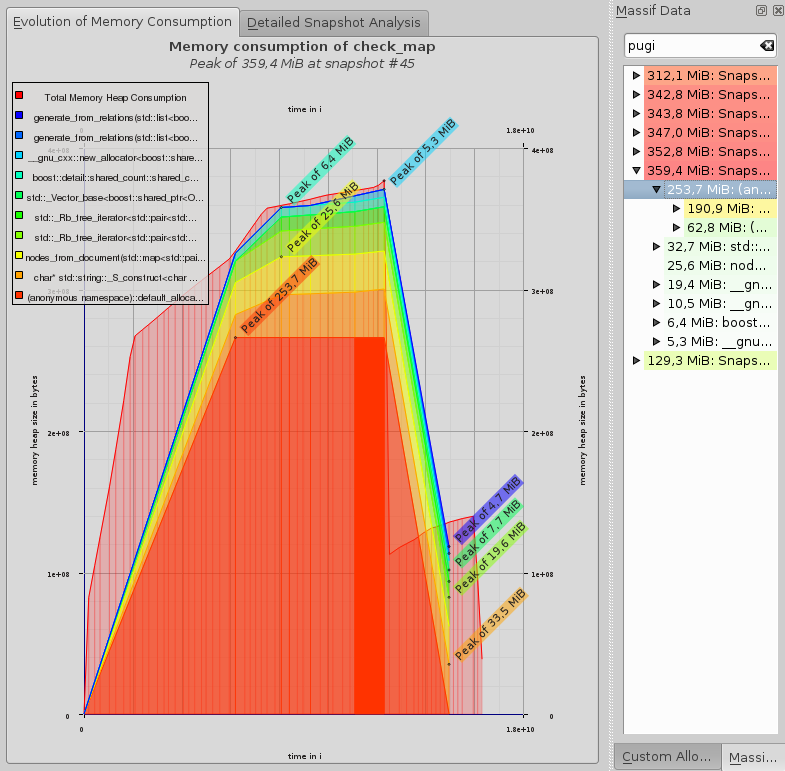
我粗略地估计了理论消耗,以了解哪个因素介于消耗和至少应该是多少之间。是10。所以我使用valgrind --tool=massif来分析内存消耗。它表明,在 350MB 的峰值时,250MB 被称为 xml_allocator 的东西使用,它源于 pugixml 库。我转到我的代码部分,在那里我实例化了 pugi::xml_document 并将 std::cout 放入对象的析构函数以确认它已被释放在我的程序中很早就发生了(最后我睡了 20 秒,以便有足够的时间来测量内存消耗,即使在析构函数的控制台输出出现后内存消耗仍保持 350MB)。
现在我不知道如何解释它,希望有人能帮助我做出错误的假设或类似的事情。
使用 pugixml 的最外层代码片段类似于:
void parse( std::string filename, my_data_structure& struc )
{
pugi::xml_document doc;
pugi::xml_parse_result result = doc.load_file(filename.c_str());
for (pugi::xml_node node = doc.child("foo").child("bar"); node; node = node.next_sibling("bar"))
{
struc.hams.push_back( node.attribute("ham").value() );
}
}
并且由于在我的代码中我没有在某处存储 pugixml 元素(仅从中提取实际值),所以我希望 doc 期望在函数 parse 还剩下,但在图表上看,我无法判断发生这种情况的位置(在时间轴上)。
最佳答案
您的假设不正确。
以下是估算 pugixml 内存消耗的方法:
- 加载文档时,文档的整个文本都会加载到内存中。所以你的文件有 50 Mb。这是来自 xml_document::load_file -> load_file_impl 的 1 个分配
- 除此之外,还有包含指向其他节点等的链接的 DOM 结构。节点的大小为 32 字节,属性的大小为 20 字节;对于 32 位进程,乘以 2 对于 64 位进程。这是来自 xml_allocator 的许多分配(每个分配大约 32kb)。
根据文档中节点/属性的密度,内存消耗范围可以从文档大小的 110%(即 50 Mb -> 55 Mb)到 600%(即 50 Mb -> 300 兆)。
当您销毁 pugixml 文档(调用 xml_document dtor)时,数据将被释放 - 然而,根据操作系统堆的行为方式,您可能不会立即看到它返回到系统 - 它可能会保留在进程堆中。验证您是否可以尝试再次进行解析并检查第二次解析后峰值内存是否相同。
关于c++ - 使用 pugixml 解释程序的内存消耗,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/17963603/