我只想根据 MAX(ts) 从表中过滤几列。 ts = 时间戳。如果我只选择两列 - deviceid 和 ts,一切都可以:
SELECT deviceid, MAX(ts)
FROM device_data
GROUP BY deviceid
结果:
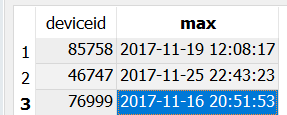
但我还需要两列 - 经度和纬度。如果我选择经度和纬度,我会遇到问题,因为它们必须出现在 GROUP BY 中,并且我使用相同的 deviceid 得到太多结果:

如何避免在 GROUP BY 中插入经度和纬度?
最佳答案
对此有多种解决方案。一种是使用窗口函数在按日期降序排列时获取同一 deviceid 的分区内的第一个经度、纬度等。
然后你会得到重复项,你可以使用 distinct 删除它们:
SELECT DISTINCT deviceid,
FIRST_VALUE(longitude) OVER win AS longitude,
FIRST_VALUE(latitude) OVER win AS latitute,
FIRST_VALUE(ts) OVER win AS ts
FROM device_data
WINDOW win AS (PARTITION BY deviceid ORDER BY ts DESC);
关于sql - 选择和分组,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/47499792/