我一直认为连接比子查询更快。然而,对于小数据集中的非常简单的查询,连接会在 1.0 秒内返回,而相关子查询会在 0.001 秒内返回。似乎有什么不对劲。我注意到这两个查询都使用了正确的(名称令人震惊的)索引。对于 Join 来说,超过 1 秒似乎过多。有什么想法吗?
请将这两个查询与其解释计划进行比较:
a) 使用联接
select user.id, user.username,
count(distinct bet_placed.id) as bets_placed,
count(distinct bet_won.id) as bets_won,
count(distinct bets_involved.id) as bets_involved
from user
left join bet as bet_placed on bet_placed.user_placed = user.id
left join bet as bet_won on bet_won.user_won = user.id
left join bet_accepters as bets_involved on bets_involved.user = user.id
group by user.id
解释计划:
id select_type table type possible_keys key key_len ref rows filtered Extra
1 SIMPLE user index PRIMARY PRIMARY 4 NULL 86 100.00 NULL
1 SIMPLE bet_placed ref fk_bet_user1_idx fk_bet_user1_idx 4 xxx.user.id 6 100.00 "Using index"
1 SIMPLE bet_won ref user_won_idx user_won_idx 5 xxx.user.id 8 100.00 "Using index"
1 SIMPLE bets_involved ref FK_user_idx FK_user_idx 4 xxx.user.id 8 100.00 "Using index"
平均响应时间:1.0秒
b) 使用相关子查询
select user.id, user.username,
(select COALESCE(count(bet.id), 0) from bet where bet.user_placed = user.id) as bets_placed,
(select COALESCE(count(bet.id), 0) from bet where bet.user_won = user.id) as bets_won,
(select COALESCE(count(bet_accepters.id), 0) from bet_accepters where bet_accepters.user = user.id) as bets_involved
from user;
解释计划:
id select_type table type possible_keys key key_len ref rows filtered Extra
1 PRIMARY user ALL NULL NULL NULL NULL 86 100.00 NULL
4 "DEPENDENT SUBQUERY" bet_accepters ref FK_user_idx FK_user_idx 4 xxx.user.id 8 100.00 "Using index"
3 "DEPENDENT SUBQUERY" bet ref user_won_idx user_won_idx 5 xxx.user.id 8 100.00 "Using index"
2 "DEPENDENT SUBQUERY" bet ref fk_bet_user1_idx fk_bet_user1_idx 4 xxx.user.id 6 100.00 "Using index"
平均响应时间:0.001秒
最佳答案
请参阅

显示不同类型查询的速度/行数比较。
“较小”的数据集可能几乎没有差异(无论哪种方式)(但数据库的设置方式以及使用的 DBMS 可能有所不同),但正如您所看到的,
但是,相对于其他“查询类型”,这些操作比其他操作要快得多(如下所示):
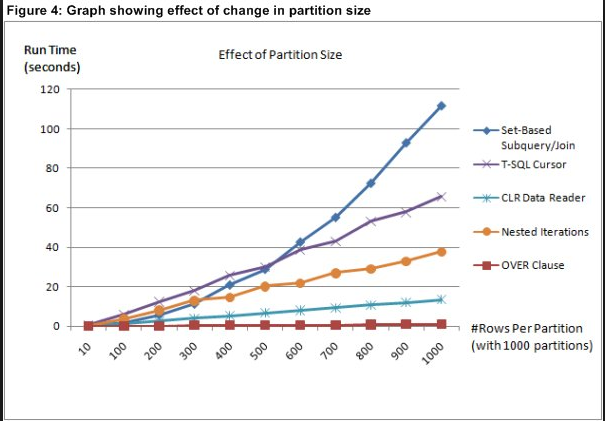
Subquery vs. Join
Both the subquery and join solutions perform reasonably well when very small partitions are involved (up to several hundred rows per partition). As partition size grows, the performance of these solutions degrades in a quadratic (N2) manner, becoming quite poor. But as long as the partitions are small, performance degradation caused by an increase in number of partitions is linear. One factor that might affect your choice between using a subquery-based or join-based solution is the number of aggregates requested. As I discussed, the subquery-based approach requires a separate scan of the data for each aggregate, whereas the join-based approach doesn’t—so you’ll most likely want to use the join approach when you need to calculate multiple aggregates.
关于Mysql 相关子查询 vs Join 性能,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/27523714/