我正在开发一个允许用户通过 facebook 注册的应用程序或 twitter我希望能够使用这些网站上的他们的个人数据,并想知道我应该如何存储这些数据。这是我到目前为止的想法:
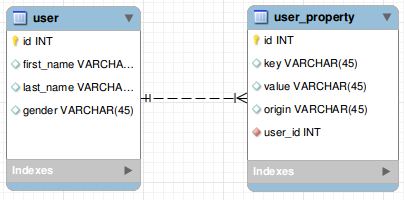
user表将存储无论用户如何注册都应该存在的信息,例如 first_name .
user_property表将用作 key-value缓存和存储特定于 facebook 的信息或 twitter (由 origin 字段表示)。我将存储可用作 API 一部分的属性电话或SQL单独查询,例如用户的 facebook id我会存储其他 API 的结果在 JSON 中序列化的调用格式,例如用户的 facebook friends .
那样:
- 我在
user中有常用信息 table 和一张单人SELECT我可以获得有关用户的一些基本有用信息 - 我有一些额外的属性来自
facebook/twitter(例如用户 ID)单独存储,我仍然可以使用JOIN进行查找在user之间和user_property. - 我仍然可以使用
JOIN检索那些成本太高而无法正常存储的信息(例如,创建一个表来存储人们的 friend 并且每个 friend 有 1 个表条目)在user之间和user_property.
这就是我现在想知道的:
问题 1:这可能是一种可持续的数据库设计,还是我弄错了并会遇到一些问题,如果是,是哪些问题?
问题 2:在存储经常更改的信息(例如 friend /追随者列表)时,您如何使信息保持最新(您首先将信息存储在数据库中吗?如果是这样,您使用什么标准/触发器来决定何时再次提取信息)?
最佳答案
您的设计具有 EAV 模式(实体-属性-值)的大多数(坏)属性。求Wikipedia在这件事上也看看这个网站。
EAV 最不可持续的设计决策是(恕我直言),一开始这似乎可以很好地扩展。但是,一旦您的数据增长,您就会高速撞到混凝土墙。这是因为为了加载一个 用户的数据,数据库必须使用随机访问 触及物理表的巨大 部分。当数据经常增长和变化时,调整数据库以将一个用户的 user_property 行保持在相邻页面中是一项繁重的任务。
关于mysql - 用于存储来自外部网站的用户数据的数据库设计模式,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/13223270/