我必须修改此代码,以便抓取 仅保留包含特定关键字的链接。就我而言,我正在抓取报纸页面以查找与“英国脱欧”一词相关的新闻。
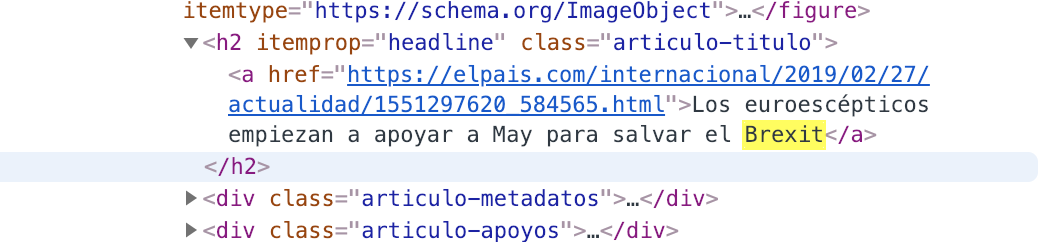
我已经尝试修改方法 parse_links 以便它只保留其中包含“Brexit”的链接(或“a”标签),但它似乎不起作用。
我应该把条件放在哪里?
import requests
from bs4 import BeautifulSoup
from queue import Queue, Empty
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urljoin, urlparse
class MultiThreadScraper:
def __init__(self, base_url):
self.base_url = base_url
self.root_url = '{}://{}'.format(urlparse(self.base_url).scheme, urlparse(self.base_url).netloc)
self.pool = ThreadPoolExecutor(max_workers=20)
self.scraped_pages = set([])
self.to_crawl = Queue(10)
self.to_crawl.put(self.base_url)
def parse_links(self, html):
soup = BeautifulSoup(html, 'html.parser')
links = soup.find_all('a', href=True)
for link in links:
url = link['href']
if url.startswith('/') or url.startswith(self.root_url):
url = urljoin(self.root_url, url)
if url not in self.scraped_pages:
self.to_crawl.put(url)
def scrape_info(self, html):
return
def post_scrape_callback(self, res):
result = res.result()
if result and result.status_code == 200:
self.parse_links(result.text)
self.scrape_info(result.text)
def scrape_page(self, url):
try:
res = requests.get(url, timeout=(3, 30))
return res
except requests.RequestException:
return
def run_scraper(self):
while True:
try:
target_url = self.to_crawl.get(timeout=60)
if target_url not in self.scraped_pages:
print("Scraping URL: {}".format(target_url))
self.scraped_pages.add(target_url)
job = self.pool.submit(self.scrape_page, target_url)
job.add_done_callback(self.post_scrape_callback)
except Empty:
return
except Exception as e:
print(e)
continue
if __name__ == '__main__':
s = MultiThreadScraper("https://elpais.com/")
s.run_scraper()
最佳答案
你需要导入re模块来获取具体的文本值。试试下面的代码。
import re
links = soup.find_all('a', text=re.compile("Brexit"))
这应该返回仅包含 Brexit 的链接。
关于python - 使用 BeautifulSoup 查找与特定关键字相关的链接,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/54926588/