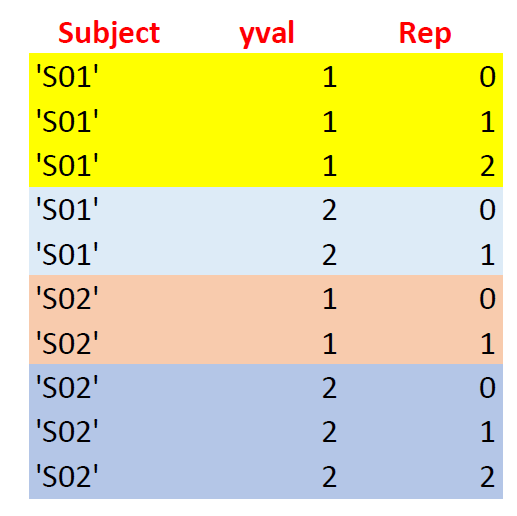
在下面的数据框中,我在三个字段上进行分组:“主题”、“代表”和“yval”。
import pandas as pd
yval = [[1]*30 + [2]*20 + [1]*20 + [2]*30 ]
yval = reduce(lambda x,y: x+y, yval)
df = pd.DataFrame({'yval': yval , 'xval':np.random.randn(100)})
df['Subject'] = ['S01'] * 50 + ['S02'] * 50
l = [[x] * 10 for x in range(3)] + [[x] * 10 for x in range(2)] + [[x] * 10 for x in range(2)] + [[x] * 10 for x in range(3)]
l = reduce(lambda x,y: x+y,l)
df['Rep'] = l
df
for k, t in df.groupby(['Subject', 'yval', 'Rep']):
print k
('S01', 1, 0)
('S01', 1, 1)
('S01', 1, 2)
('S01', 2, 0)
('S01', 2, 1)
('S02', 1, 0)
('S02', 1, 1)
('S02', 2, 0)
('S02', 2, 1)
('S02', 2, 2)
我正在尝试找到一种方法来从每个组中选择 n 行。在此示例中,假设 n = 2,我们可能会得到以下结果。如果 n=4,我期望一切(整个数据帧)。
('S01', 1, 0)
('S01', 1, 2)
('S01', 2, 0)
('S01', 2, 1)
('S02', 1, 0)
('S02', 1, 1)
('S02', 2, 1)
('S02', 2, 2)
最佳答案
上一个答案选择了 n groups,而 OP 希望从每个组中选择 n 行。那么应该这样做
ix = np.hstack([np.random.choice(v, n, replace=False) for v in gps.groups.values()])
其中 gps = df.groupby(['Subject', 'yval', 'Rep'])。
然后 df.iloc(ix) 将从每组中随机选择 n 行。
关于python - 从 Pandas 的每组中抽取 n 行,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40621079/