我在这里问了我之前的问题:
Xpath pulling number in table but nothing after next span
这很有效,我设法在一个名为 xpath checker 的 firefox 插件中看到了我想要的数字。结果如下所示。

所以我知道我可以用这个 xpath 找到这个数字,但是当尝试运行 python 脚本来查找并保存这个数字时,它说找不到它。
try:
views = browser.find_element_by_xpath("//div[@class='video-details-inside']/table//span[@class='added-time']/preceding-sibling::text()")
except NoSuchElementException:
print "NO views"
views = 'n/a'
pass
我不认为通过不是最佳实践,但我现在只是在测试这个,试图找到这个数字。我想知道我是否需要更改 xpath 末尾的某些内容,例如 .text,因为 xpath 检查器通常显示的结果略有不同。如下所示:
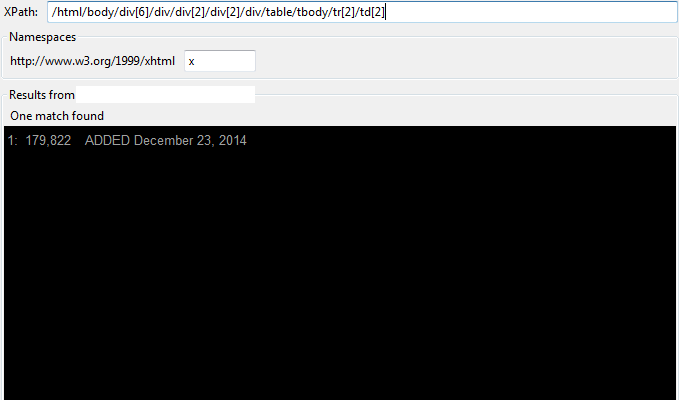
我需要使用我提供的 xpath 而不是上图中使用的 xpath,因为我只想要数字而不是日期。您可以在我之前的问题中看到部分来源。
提前致谢!在这里挠我的头。
最佳答案
find_element_by_xpath() 中使用的 xpath 必须指向一个元素,而不是文本节点和属性。这一点很关键。
这里最简单的方法是:
- 获取
td的文本(父级) - 获取
span的文本(子) - 从 parent 的文本中删除 child 的文本
代码:
span = browser.find_element_by_xpath("//div[@class='video-details-inside']/table//span[@class='added-time']")
td = span.find_element_by_xpath('..')
views = td.text.replace(span.text, '').strip()
关于Python 爬虫找不到特定的 Xpath,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/27618733/