我正在尝试解析 this link 中的表转换为结构化数据类型,例如DataFrame 或 json 或类似的东西。然而,我尝试过的所有方法似乎都行不通,包括 requests、pandas.read_html。
最后我发现是因为从网页获取的HTML没有包含表格中的信息。例如,字符串 "贵广转债" 显然存在于表体中,但在页面源代码中不存在(ctrl+F 没有匹配)!但是,当您右键单击并转到检查单元格时,此字符串就会出现。


看来,如果我可以在Inspect -> Elements 面板中获取信息,那么我也许能够解析该表。我怎样才能做到这一点?
最佳答案
对于使用ajax请求加载数据的动态页面,请尝试监视开发人员工具中的网络选项卡(F12)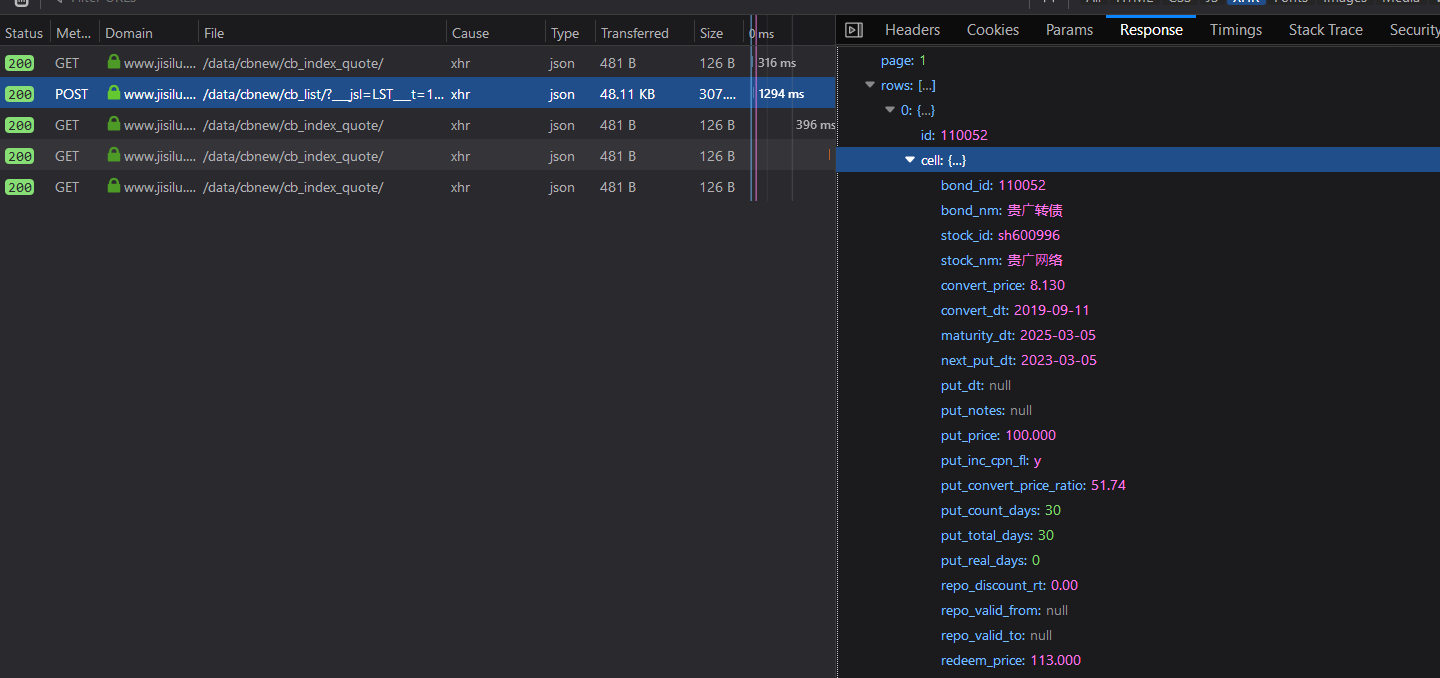 ,然后找到您需要的请求。
,然后找到您需要的请求。
这里的股票代码数据是从https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___t=1561977181934
POST https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___t=1561977181934
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:68.0) Gecko/20100101 Firefox/68.0
Accept: application/json, text/javascript, */*; q=0.01
Accept-Language: en-US,de-DE;q=0.7,en;q=0.3
Referer: https://www.jisilu.cn/data/cbnew/
X-Requested-With: XMLHttpRequest
Connection: keep-alive
Cookie: kbzw__Session=7n47d42nc28n259v722k8onhq5; kbz_newcookie=1
Cache-Control: max-age=0
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
fprice=&tprice=&volume=&svolume=&premium_rt=&ytm_rt=&rating_cd=&is_search=N&btype=&listed=Y&industry=&bond_ids=&rp=50&page=1
<> 2019-07-01T013533.200.json
然后,您可以使用 requests 库或任何其他 http 客户端来获取 json(如果需要,请记住提供 headers/cookie),然后使用您喜欢的 JSON。
Python
使用这些信息,您可以使用 requests 库,如下所示:
import requests
if __name__ == '__main__':
data = {
'fprice': '',
'tprice': '',
'volume': '',
'svolume': '',
'premium_rt': '',
'ytm_rt': '',
'rating_cd': '',
'is_search': 'N',
'btype': '',
'listed': 'Y',
'industry': '',
'bond_ids': '',
'rp': '50',
'page': '',
}
res = requests.post('https://www.jisilu.cn/data/cbnew/cb_list/?___jsl=LST___t=1561977181934',
data=data)
res.raise_for_status()
data = res.json()
print(data)
这给了你一个非常大的列表:
{'page': 1, 'rows': [{'id': '110052', 'cell': {'bond_id': '110052', 'bond_nm': '贵广转债', 'stock_id': 'sh600996', 'stock_nm': '贵广 ... and goes on much longer
关于Python从网页解析表格,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56833980/