我有一组数据,如附件原始数据,当我通过sort -n对原始数据进行排序时,数据逐行排序,输出看起来像这样:
3 6 9 22
2 3 4 5
1 7 16 20
我想按列方式对数据进行排序,输出如下所示:
1 2 4 3
3 6 9 16
5 7 20 22
好的,我确实尝试了一些东西。
我的主要理想是按列提取数据然后排序然后粘贴它们,但我无法通过。这是我的脚本:
for ((i=1; i<=4; i=i+1))
do
awk '{print $i}' file | sort -n >>output
done
输出:
1 7 20 16
3 6 9 22
5 2 4 3
1 7 20 16
3 6 9 22
5 2 4 3
1 7 20 16
3 6 9 22
5 2 4 3
1 7 20 16
3 6 9 22
5 2 4 3
看来$i是不变的,等于$0
非常感谢。
raw data1
3 6 9 22
5 2 4 3
1 7 20 16
raw data2
488.000000 1236.000000 984.000000 2388.000000 788.000000 704.000000
600.000000 1348.000000 872.000000 2500.000000 900.000000 816.000000
232.000000 516.000000 1704.000000 1668.000000 68.000000 16.000000
244.000000 504.000000 1716.000000 1656.000000 56.000000 28.000000
2340.000000 3088.000000 868.000000 4240.000000 2640.000000 2556.000000
2588.000000 3336.000000 1116.000000 4488.000000 2888.000000 2804.000000
最佳答案
让我介绍一个使用 cut 和 sort 的灵活解决方案,您可以在任何 M,N 大小的制表符分隔输入矩阵上使用它。
$ cat -vTE data_to_sort.in
3^I6^I9^I22$
5^I2^I4^I3$
1^I7^I20^I16$
$ col=4; line=3;
$ for i in $(seq ${col}); do cut -f$i data_to_sort.in |\
> sort -n; done | paste $(for i in $(seq ${line}); do echo -n "- "; done) |\
> datamash transpose
1 2 4 3
3 6 9 16
5 7 20 22
如果输入文件不是 \t 分隔符,您需要定义正确的分隔符以使用 -d"$DELIM_CHAR" 使剪切正常工作。
for i in $(seq ${col});做 cut -f$i data_to_sort.in |排序-n; done将文件的每一列分开并排序paste $(for i in $(seq ${line}); do echo -n "- "; done)然后粘贴列将重新创建一个矩阵结构datamash transpose需要转置中间矩阵
感谢Sundeep的反馈,让我向您介绍一个使用pr而不是paste的更好解决方案> 生成列的命令:
$ col=4; line=3
$ for i in $(seq ${col}); do cut -f$i data_to_sort.in |\
> sort -n; done | pr -${line}ats | datamash transpose
最后一点,
$ col=4; for i in $(seq ${col}); do cut -f$i data_to_sort.in |\
> sort -n; done | pr -${col}ts
1 2 4 3
3 6 9 16
5 7 20 22
以下解决方案将允许我们完全不使用 datamash!!!
(非常感谢 Sundeep)
对怀疑论者和反对者有效的证据...
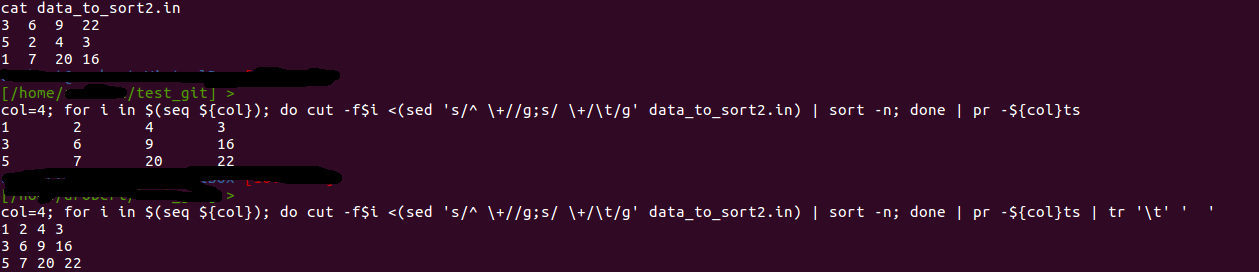
第二次运行 6 列:
$ col=6; for i in $(seq ${col}); do cut -f$i <(sed 's/^ \+//g;s/ \+/\t/g' data2) | sort -n; done | pr -${col}ts | tr '\t' ' '
232.000000 504.000000 868.000000 1656.000000 56.000000 16.000000
244.000000 516.000000 872.000000 1668.000000 68.000000 28.000000
488.000000 1236.000000 984.000000 2388.000000 788.000000 704.000000
600.000000 1348.000000 1116.000000 2500.000000 900.000000 816.000000
2340.000000 3088.000000 1704.000000 4240.000000 2640.000000 2556.000000
2588.000000 3336.000000 1716.000000 4488.000000 2888.000000 2804.000000

关于linux - 如何按列对一组数据进行排序?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/49185119/