我有一些轮廓图像,我想对其进行分割,这基本上意味着我想将轮廓图像中的所有字符保存到单独的图像中。但我得到了几张噪声图像以及所需的输出。我想知道如何在不影响所需输出的情况下去除所有噪声图像。
我试图更改 w 和 h 的值,以便最大限度地减少噪音并仅获取字符作为分段图像。
def imageSegmentation(fldr):
for file in fldr:
for f in os.listdir(file):
im = cv2.imread(file+f)
#print(f)
imgray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(imgray, 127, 255, 0)
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
con_img=cv2.drawContours(im, contours, -1, (0,0,0), 1)
#cv2.imshow("Contour_Image",con_img)
#cv2.waitKey(0)
#cv2.destroyAllWindows()
newfolder=file+"\\contour\\"+f+"\\"
os.makedirs(newfolder, exist_ok=True)
fname=os.path.splitext(f)[0]
cv2.imwrite((newfolder+fname+".png"),con_img)
#cv2.imshow("con_img",con_img)
#cv2.waitKey()
#cv2.destroyAllWindows()
newfolder2=file+"\\seg\\"+fname+"\\"
os.makedirs(newfolder2,exist_ok=True)
sorted_ctrs = sorted(contours, key=lambda cntr: cv2.boundingRect(cntr)[0])
for i, cntr in enumerate(sorted_ctrs):
# Get bounding box
x, y, w, h = cv2.boundingRect(cntr)
# Getting ROI
roi = im[y:y + h, x:x + w]
#roi=~roi
if w > 9 and h > 27:
cv2.imwrite(newfolder2+"{}.png".format(i), roi)
我想知道如何仅获取正确的字符图像,排除输出文件夹中的噪声图像。我添加了一些输入轮廓图像,我需要将它们分割成单个字符。


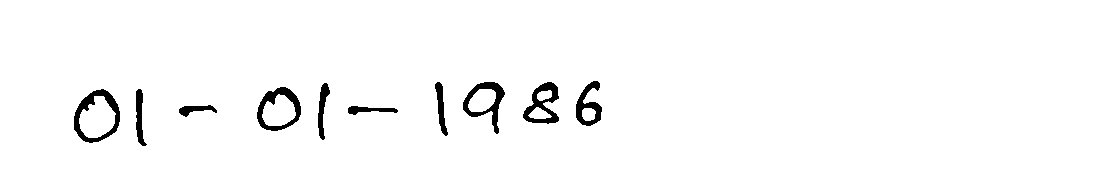


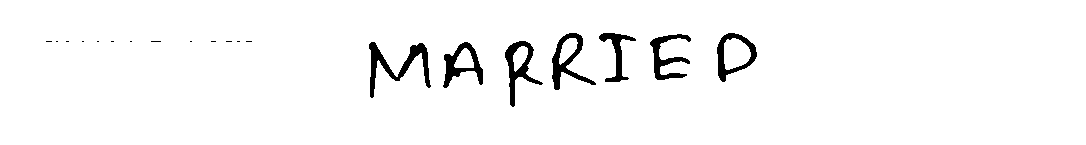
最佳答案
由于您的问题不完全清楚您是想提取单个字符还是整个单词,因此以下是同时执行这两种操作的方法。
单个角色
这里的主要思想是
- 将图像转换为灰度和高斯模糊
- 执行canny边缘检测
- 查找轮廓
- 迭代轮廓并使用最小面积进行过滤
- 获取边界框并提取 ROI
使用cv2.Canny()进行Canny边缘检测

现在我们使用 cv2.findContours() 迭代轮廓并使用 cv2.contourArea() 进行过滤,然后绘制边界框

这是您的一些其他输入图像的结果

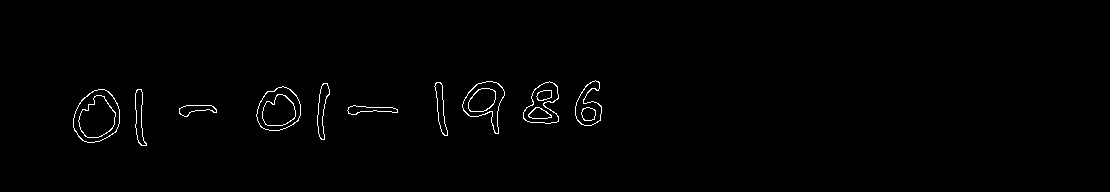
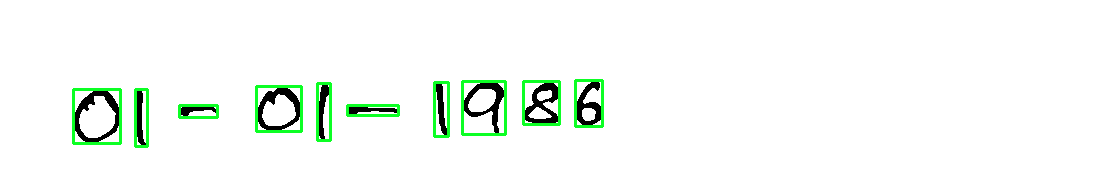
import cv2
image = cv2.imread('1.png')
original = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0)
canny = cv2.Canny(blur, 120, 255, 1)
cnts = cv2.findContours(canny, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
min_area = 100
image_number = 0
for c in cnts:
area = cv2.contourArea(c)
if area > min_area:
x,y,w,h = cv2.boundingRect(c)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2)
ROI = original[y:y+h, x:x+w]
cv2.imwrite("ROI_{}.png".format(image_number), ROI)
image_number += 1
cv2.imshow('blur', blur)
cv2.imshow('canny', canny)
cv2.imshow('image', image)
cv2.waitKey(0)
整个单词
现在如果你想提取整个单词,你必须稍微修改一下策略
- 将图像转换为灰度和高斯模糊
- 执行canny边缘检测
- 扩张以获得单个轮廓
- 查找轮廓
- 迭代轮廓并使用最小面积进行过滤
- 获取边界框并提取 ROI
Canny 边缘检测

使用cv2.dilate()进行扩张以连接轮廓

使用轮廓区域查找边界框并进行过滤

提取的投资返回率

注意:如果您尝试查找整个单词,您可能必须更改最小面积值,因为它取决于您正在分析的图像。
import cv2
image = cv2.imread('1.png')
original = image.copy()
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.GaussianBlur(gray, (3,3), 0)
canny = cv2.Canny(blur, 120, 255, 1)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (9,9))
dilate = cv2.dilate(canny, kernel, iterations=5)
cnts = cv2.findContours(dilate, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
cnts = cnts[0] if len(cnts) == 2 else cnts[1]
min_area = 5000
image_number = 0
for c in cnts:
area = cv2.contourArea(c)
if area > min_area:
x,y,w,h = cv2.boundingRect(c)
cv2.rectangle(image, (x, y), (x + w, y + h), (36,255,12), 2)
ROI = original[y:y+h, x:x+w]
cv2.imwrite("ROI_{}.png".format(image_number), ROI)
image_number += 1
cv2.imshow('blur', blur)
cv2.imshow('dilate', dilate)
cv2.imshow('canny', canny)
cv2.imshow('image', image)
cv2.waitKey(0)
关于python - 如何将图像中的字符和单词分割成轮廓,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56698714/