题
在 R 中进行探索性分析时,使用在重复试验中积累的分类标签来构建多元数据的正确方法是什么?我不想回到 MATLAB。
解释
我比 MATLAB 更喜欢 R 的分析函数和语法(以及令人惊叹的图),并且一直在努力重构我的东西。但是,我一直对工作中组织数据的方式感到困惑。
MATLAB
我通常使用在多次试验中重复的多元时间序列,这些时间序列存储在 SERIESxSAMPLESxTRIALS 的大矩阵 rank-3 张量多维数组中。这偶尔适用于一些不错的线性代数内容,但在涉及另一个变量(即 CLASS)时就显得笨拙了。通常,类标签存储在另一个维度为 1x TRIALS 的向量中。 .
说到分析,我基本上尽量少画图,因为要绘制出一个非常好的图需要很多工作,才能教你很多关于 MATLAB 数据的知识。 ( I'm not the only one who feels this way )。
电阻
在 R 中,我一直尽可能接近 MATLAB 结构,但是当试图将类标记分开时,事情变得非常复杂;即使我只使用它们的属性,我也必须继续将标签传递给函数。所以我所做的是将数组按 CLASS 分成一个数组列表。这增加了我所有 apply() 的复杂性功能,但在保持一致(和错误排除)方面似乎是值得的。
另一方面,R 似乎对张量/多维数组并不友好。要与他们合作,您需要获取 abind图书馆。 multivariate analysis, like this example 上的文档似乎在假设你有一个巨大的二维数据点表的情况下运作,就像一些中世纪的长卷轴数据框,并且没有提到如何从我所在的地方到达“那里”。
一旦我开始对处理过的数据进行绘图和分类,这就不是什么大问题了,因为到那时我已经开始使用像 TRIALSxFEATURES 这样的形状对数据框友好的结构(melt 在这方面有很大帮助)。另一方面,如果我想为探索阶段(即统计矩、分离、类内/类间方差、直方图等)快速生成散点图矩阵或点阵直方图集,我必须停下来弄清楚如何我要去apply()这些巨大的多维数组变成了那些库可以理解的东西。
如果我继续在丛林中为此想出特别的解决方案,我要么永远不会变得更好,要么我最终会以我自己奇怪的巫师方式来做这件事,对任何人都没有意义.
那么,用在 R 中进行探索性分析的重复试验中积累的分类标签来构建多元数据的正确方法是什么?拜托,我不想回到 MATLAB。
奖励:我倾向于对多个主题的相同数据结构重复这些分析。有没有比将代码块包装成 for 更好的通用方法?循环?
最佳答案
正如已经指出的那样,许多更强大的分析和可视化工具依赖于长格式的数据。当然,对于从矩阵代数中受益的转换,您应该将内容保存在数组中,但是一旦您想要对数据子集运行并行分析,或按数据中的因素绘制内容,您真的想要 melt .
这是一个让您开始使用 data.table 的示例和 ggplot .
数组 -> 数据表
首先,让我们以您的格式制作一些数据:
series <- 3
samples <- 2
trials <- 4
trial.labs <- paste("tr", seq(len=trials))
trial.class <- sample(c("A", "B"), trials, rep=T)
arr <- array(
runif(series * samples * trials),
dim=c(series, samples, trials),
dimnames=list(
ser=paste("ser", seq(len=series)),
smp=paste("smp", seq(len=samples)),
tr=trial.labs
)
)
# , , tr = Trial 1
# smp
# ser smp 1 smp 2
# ser 1 0.9648542 0.4134501
# ser 2 0.7285704 0.1393077
# ser 3 0.3142587 0.1012979
#
# ... omitted 2 trials ...
#
# , , tr = Trial 4
# smp
# ser smp 1 smp 2
# ser 1 0.5867905 0.5160964
# ser 2 0.2432201 0.7702306
# ser 3 0.2671743 0.8568685
现在我们有一个 3 维数组。让我们
melt并将其变成 data.table (注意 melt 在 data.frames 上运行,基本上是 data.table s sans bells & whisles,所以我们必须先融化,然后转换为 data.table ):library(reshape2)
library(data.table)
dt.raw <- data.table(melt(arr), key="tr") # we'll get to what the `key` arg is doing later
# ser smp tr value
# 1: ser 1 smp 1 tr 1 0.53178276
# 2: ser 2 smp 1 tr 1 0.28574271
# 3: ser 3 smp 1 tr 1 0.62991366
# 4: ser 1 smp 2 tr 1 0.31073376
# 5: ser 2 smp 2 tr 1 0.36098971
# ---
# 20: ser 2 smp 1 tr 4 0.38049334
# 21: ser 3 smp 1 tr 4 0.14170226
# 22: ser 1 smp 2 tr 4 0.63719962
# 23: ser 2 smp 2 tr 4 0.07100314
# 24: ser 3 smp 2 tr 4 0.11864134
请注意这是多么容易,我们所有的维度标签都会渗透到长格式。
data.tables的花里胡哨之一是在 data.table 之间进行索引合并的能力s(很像 MySQL 索引连接)。所以在这里,我们将这样做来绑定(bind) class到我们的数据:dt <- dt.raw[J(trial.labs, class=trial.class)] # on the fly mapping of trials to class
# tr ser smp value class
# 1: Trial 1 ser 1 smp 1 0.9648542 A
# 2: Trial 1 ser 2 smp 1 0.7285704 A
# 3: Trial 1 ser 3 smp 1 0.3142587 A
# 4: Trial 1 ser 1 smp 2 0.4134501 A
# 5: Trial 1 ser 2 smp 2 0.1393077 A
# ---
# 20: Trial 4 ser 2 smp 1 0.2432201 A
# 21: Trial 4 ser 3 smp 1 0.2671743 A
# 22: Trial 4 ser 1 smp 2 0.5160964 A
# 23: Trial 4 ser 2 smp 2 0.7702306 A
# 24: Trial 4 ser 3 smp 2 0.8568685 A
需要理解的几点:
J创建一个 data.table来自矢量 data.table 的行进行子集化使用另一个数据表(即使用 data.table 作为 [.data.table 中大括号后的第一个参数)导致 data.table在这种情况下,将外部表(在这种情况下为 dt)左连接(在 MySQL 中)到内部表(由 J 动态创建的表)。连接在 key 上完成外列 data.table ,您可能已经注意到我们在 melt 中定义的/data.table转换步骤提前。 你必须阅读文档才能完全理解发生了什么,但想想
J(trial.labs, class=trial.class)实际上等效于创建一个 data.table与 data.table(trial.labs, class=trial.class) ,除了 J仅在内部使用时有效 [.data.table .所以现在,通过一个简单的步骤,我们将类数据附加到值上。同样,如果您需要矩阵代数,请先对数组进行操作,然后用两三个简单的命令切换回长格式。正如评论中所指出的,除非您有充分的理由这样做,否则您可能不想在长格式和数组格式之间来回切换。
一旦事情在
data.table ,您可以很容易地对数据进行分组/聚合(类似于拆分-应用-组合样式的概念)。假设我们想要获取每个 class 的汇总统计信息。 - sample组合:dt[, as.list(summary(value)), by=list(class, smp)]
# class smp Min. 1st Qu. Median Mean 3rd Qu. Max.
# 1: A smp 1 0.08324 0.2537 0.3143 0.4708 0.7286 0.9649
# 2: A smp 2 0.10130 0.1609 0.5161 0.4749 0.6894 0.8569
# 3: B smp 1 0.14050 0.3089 0.4773 0.5049 0.6872 0.8970
# 4: B smp 2 0.08294 0.1196 0.1562 0.3818 0.5313 0.9063
在这里,我们只给
data.table对每个 as.list(summary(value)) 求值的表达式 ( class ) , smp数据的子集(在 by 表达式中指定)。我们需要as.list以便通过 data.table 重新组合结果作为列。您可以轻松地为类/样本/试验/系列变量的任何组合计算矩(例如
list(mean(value), var(value), (value - mean(value))^3 )。如果您想对数据进行简单的转换,使用
data.table 非常容易。 :dt[, value:=value * 10] # modify in place with `:=`, very efficient
dt[1:2] # see, `value` now 10x
# tr ser smp value class
# 1: Trial 1 ser 1 smp 1 9.648542 A
# 2: Trial 1 ser 2 smp 1 7.285704 A
这是一个就地转换,因此没有内存副本,因此速度很快。一般
data.table尝试尽可能有效地使用内存,因此是进行此类分析的最快方法之一。从长格式绘图
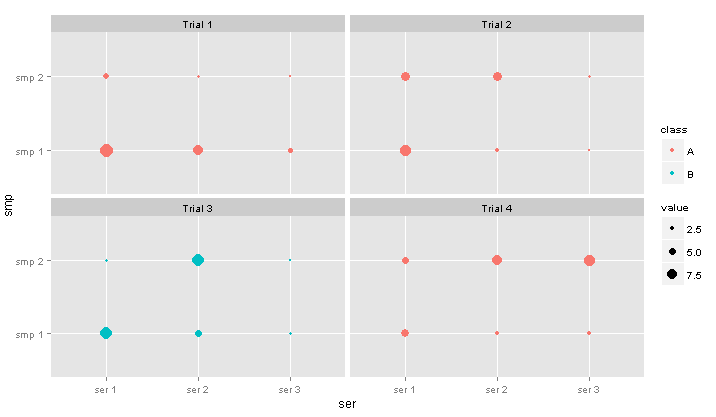
ggplot非常适合以长格式绘制数据。我不会详细介绍正在发生的事情,但希望这些图片能让您了解您可以做什么library(ggplot2)
ggplot(data=dt, aes(x=ser, y=smp, color=class, size=value)) +
geom_point() +
facet_wrap( ~ tr)
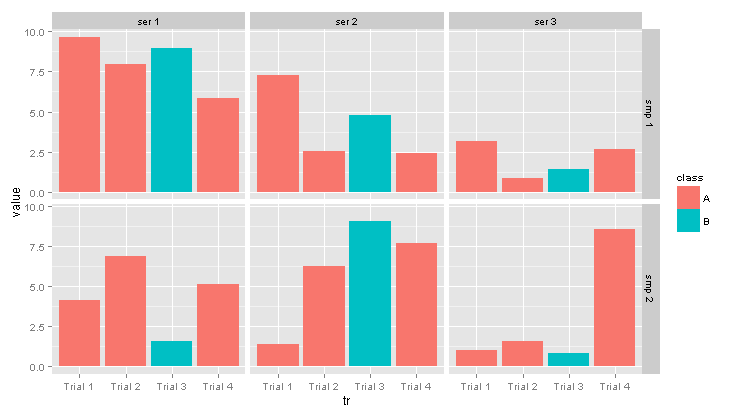
ggplot(data=dt, aes(x=tr, y=value, fill=class)) +
geom_bar(stat="identity") +
facet_grid(smp ~ ser)
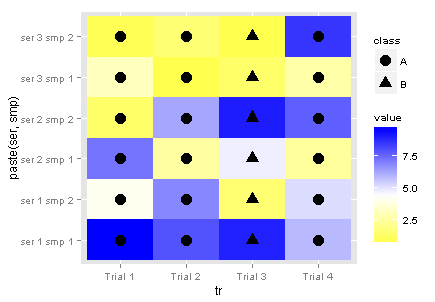
ggplot(data=dt, aes(x=tr, y=paste(ser, smp))) +
geom_tile(aes(fill=value)) +
geom_point(aes(shape=class), size=5) +
scale_fill_gradient2(low="yellow", high="blue", midpoint=median(dt$value))
数据表 -> 数组 -> 数据表
首先我们需要
acast (来自包 reshape2 )我们的数据表回到一个数组:arr.2 <- acast(dt, ser ~ smp ~ tr, value.var="value")
dimnames(arr.2) <- dimnames(arr) # unfortunately `acast` doesn't preserve dimnames properly
# , , tr = Trial 1
# smp
# ser smp 1 smp 2
# ser 1 9.648542 4.134501
# ser 2 7.285704 1.393077
# ser 3 3.142587 1.012979
# ... omitted 3 trials ...
此时,
arr.2看起来就像 arr确实如此,除了值乘以 10。注意我们必须删除 class柱子。现在,让我们做一些简单的矩阵代数shuff.mat <- matrix(c(0, 1, 1, 0), nrow=2) # re-order columns
for(i in 1:dim(arr.2)[3]) arr.2[, , i] <- arr.2[, , i] %*% shuff.mat
现在,让我们回到长格式
melt .请注意 key争论:dt.2 <- data.table(melt(arr.2, value.name="new.value"), key=c("tr", "ser", "smp"))
最后,让我们一起回来
dt和 dt.2 .在这里你需要小心。 data.table的行为是如果外表没有键,内表将根据内表的所有键连接到外表。如果内表有键,data.table将键连接到键。这是一个问题,因为我们预期的外部表,dt已经只有一个 key tr从之前开始,所以我们的连接只会发生在该列上。因此,我们需要将 key 放在外部表上,或者重置 key (我们在这里选择了后者):setkey(dt, tr, ser, smp)
dt[dt.2]
# tr ser smp value class new.value
# 1: Trial 1 ser 1 smp 1 9.648542 A 4.134501
# 2: Trial 1 ser 1 smp 2 4.134501 A 9.648542
# 3: Trial 1 ser 2 smp 1 7.285704 A 1.393077
# 4: Trial 1 ser 2 smp 2 1.393077 A 7.285704
# 5: Trial 1 ser 3 smp 1 3.142587 A 1.012979
# ---
# 20: Trial 4 ser 1 smp 2 5.160964 A 5.867905
# 21: Trial 4 ser 2 smp 1 2.432201 A 7.702306
# 22: Trial 4 ser 2 smp 2 7.702306 A 2.432201
# 23: Trial 4 ser 3 smp 1 2.671743 A 8.568685
# 24: Trial 4 ser 3 smp 2 8.568685 A 2.671743
请注意
data.table通过匹配键列来执行连接,即 - 通过将外部表的第一个键列匹配到内部表的第一列/键,将第二个匹配到第二个,依此类推,不考虑列名(有一个 FR here)。如果您的表/键的顺序不同(就像这里的情况,如果您注意到的话),您要么需要对列重新排序,要么确保两个表在您想要的列上都按相同的顺序排列键(我们在这里做了什么)。列的顺序不正确的原因是因为我们第一次加入该类,该加入是在 tr 上加入的。并导致该列成为 data.table 中的第一列.
关于arrays - R 与 MATLAB 中高维数据结构化的方法论,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/21074240/