我正在尝试使用涉及搜索另一个 DataFrame 的特定条件替换 df DataFrame 的 air_store_id 列中的 NaN 值:
data = { 'air_store_id': [ 'air_a1', np.nan, 'air_a3', np.nan, 'air_a5' ],
'hpg_store_id': [ 'hpg_a1', 'hpg_a2', np.nan, 'hpg_a4', np.nan ],
'Test': [ 'Alpha', 'Beta', 'Gamma', 'Delta', 'Epsilon' ]
}
df = pd.DataFrame(data)
display(df)

当在 df.air_store_id 中发现 NaN 时,我想使用 df.hpg_store_id 中的值(当有一个时)将其与同一列进行比较在另一个名为 id_table_df 的 DataFrame 中,并检索其 air_store_id。
这是 id_table_df 的样子:
ids_data = { 'air_store_id': [ 'air_a1', 'air_a4', 'air_a3', 'air_a2' ],
'hpg_store_id': [ 'hpg_a1', 'hpg_a4', 'hpg_a3', 'hpg_a2' ] }
id_table_df = pd.DataFrame(ids_data)
display(id_table_df)

简单地说,对于 df.air_store_id 中的每个 NaN,通过比较 df 将其替换为 与 id_table_df.air_store_id 中的适当等效.hpg_store_idid_table_df.hpg_store_id。
在这种情况下,id_table_df 最终用作查找表。生成的 DataFrame 如下所示:
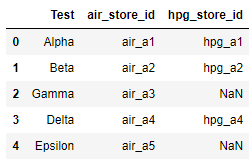
我已使用以下指令执行 tried to merge them,但出现错误:
df.loc[df.air_store_id.isnull(), 'air_store_id'] = df.merge(id_table_df, on='hpg_store_id', how='left')['air_store_id']
错误信息:
KeyError Traceback (most recent call last)
~\Anaconda3\lib\site-packages\pandas\core\indexes\base.py in get_loc(self, key, method, tolerance)
2441 try:
-> 2442 return self._engine.get_loc(key)
2443 except KeyError:
...
...
...
KeyError: 'air_store_id'
问题 1:我怎样才能完成?
问题 2:有没有办法同时对两列(air_store_id 和 hpg_store_id)执行此操作?如果可能的话,我就不必为每一列单独运行合并。
最佳答案
在 id_table_df 上使用 set_index 之后使用 pd.Series.map
df.fillna(
df.hpg_store_id.map(
id_table_df.set_index('hpg_store_id').air_store_id
).to_frame('air_store_id')
)
Test air_store_id hpg_store_id
0 Alpha air_a1 hpg_a1
1 Beta air_a2 hpg_a2
2 Gamma air_a3 NaN
3 Delta air_a4 hpg_a4
4 Epsilon air_a5 NaN
同时
v = id_table_df.values
a2h = dict(v)
h2a = dict(v[:, ::-1])
df.fillna(
pd.concat([
df.hpg_store_id.map(h2a),
df.air_store_id.map(a2h),
], axis=1, keys=['air_store_id', 'hpg_store_id'])
)
Test air_store_id hpg_store_id
0 Alpha air_a1 hpg_a1
1 Beta air_a2 hpg_a2
2 Gamma air_a3 hpg_a3
3 Delta air_a4 hpg_a4
4 Epsilon air_a5 NaN
创意解决方案
需要 Python 3
v = id_table_df.values
a2h = dict(v)
h2a = dict(v[:, ::-1])
col = id_table_df.columns
swch = dict(zip(col, col[::-1]))
df.fillna(df.applymap({**a2h, **h2a}.get).rename(columns=swch))
Test air_store_id hpg_store_id
0 Alpha air_a1 hpg_a1
1 Beta air_a2 hpg_a2
2 Gamma air_a3 hpg_a3
3 Delta air_a4 hpg_a4
4 Epsilon air_a5 None
关于python - 通过将另一列与第二个 DataFrame 进行比较来替换一列中的值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/49203723/