我正在研究 ICA实现基于假设,即所有源信号都是独立的。所以我检查了Dependence vs. Correlation的基本概念并试图显示 this示例数据示例
from numpy import *
from numpy.random import *
k = 1000
s = 10000
mn = 0
mnPow = 0
for i in arange(1,k):
a = randn(s)
a = a-mean(a)
mn = mn + mean(a)
mnPow = mnPow + mean(a**3)
print "Mean X: ", mn/k
print "Mean X^3: ", mnPow/k
但我无法生成此示例的最后一步 E(X^3) = 0:
>> Mean X: -1.11174580826e-18
>> Mean X^3: -0.00125229267144
第一个值我认为是零,但第二个值太大了,不是吗?因为我减去了 a 的平均值,所以我预计 a^3 的平均值也为零。问题是否出在
- 随机数生成器,
- 数值精度
- 我对均值和期望值的概念有误解吗?
最佳答案
样本均值本身就是一个随机变量。虽然这里的预期值为零,但具体实现 will fluctuate around that expected value .
当我多次运行以下命令时:
from numpy import *
from numpy.random import *
k = 1000
s = 10000
mn = 0
mnPow = 0
for i in arange(k):
a = randn(s)
mn += mean(a)
mnPow += mean(a**3)
print "Mean X: ", mn/k
print "Mean X^3: ", mnPow/k
我得到的数字都在零附近波动。
编辑:
如果绘制它的密度图,均值本身看起来是高斯分布的:
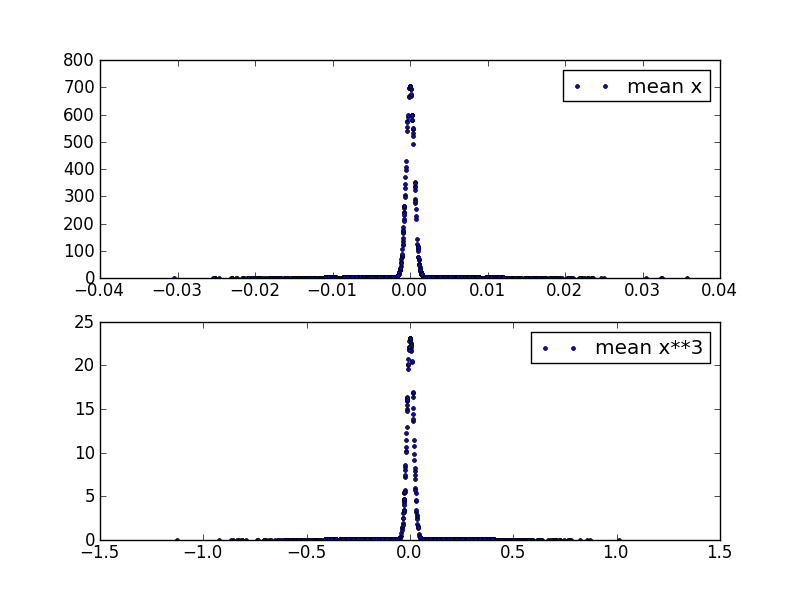
请注意,我已从您的代码中删除了 a = a-mean(a),因为它是错误的。有了它,mn 累积 mean(a - mean(a)) 由于 linearity of expectation 而在数学上为零:
E[x - E[x]] = E[x] - E[E[x]] = E[x] - E[x] = 0
结果略微非零的唯一原因是舍入误差。
关于python - 样本集和动力样本集的平均值,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/13805343/