背景
我有一个模拟人群的数据集。它们具有以下属性
- 年龄(0-120岁)
- 性别(男、女)
- 种族(白人、黑人、西类牙裔、亚裔、其他)
df.head()
Age Race Gender in_population
0 32 0 0 1
1 53 0 0 1
2 49 0 1 1
3 12 0 0 1
4 28 0 0 1
还有另一个变量将个体标识为“In_Population”*,这是一个 bool 变量。我在 Pandas 中使用 groupby 对人口进行分组,这 3 个属性的可能组合通过对每个可能的人类别中的“In_Population”变量求和来计算计数表。
人口中的每个人都可能属于 2 个性别 * 5 个种族 * 121 个年龄 = 1210 个可能的群体。
如果特定年份的特定人群没有成员(例如 0 岁男性“其他”),那么我仍然希望该组显示在我的分组数据框中,但计数为零.这在下面的数据样本中正确发生(年龄 = 0,性别 = {0,1},种族 = 4)。在这个特定的地方没有“其他”零岁 child
grouped_obj = df.groupby( ['Age','Gender','Race'] )
groupedAGR = grouped_obj.sum()
groupedAGR.head(10)
in_population
Age Gender Race
0 0 0 16
1 8
2 63
3 5
4 0
1 0 22
1 4
2 64
3 12
4 0
问题
这只发生在某些年龄-性别-种族组合中。 有时零和组会被完全跳过。以下是 45 岁的数据。我原以为会看到 0,这表明该数据集中没有 45 岁的男性“其他”种族。
>>> groupedAGR.xs( 45, level = 'Age' )
in_population
Gender Race
0 0 515
1 68
2 40
3 20
1 0 522
1 83
2 48
3 29
4 3
注意事项
*“In_Population” 在计算“死亡率”时,基本过滤掉不属于相关人群的“新生儿”和“移民”;人口死亡发生在移民和出生之前,所以我将他们排除在计算之外。我怀疑这与它有关 - 零岁 child 显示零计数,但其他所有年龄组根本没有显示任何东西......但事实并非如此。
>>> groupedAGR.xs( 88, level = 'Age' )
in_population
Gender Race
0 0 52
2 1
3 0
1 0 62
1 3
2 5
3 3
4 1
人口中没有 88 岁的亚洲男性,因此该类别为零。人口中也没有 88 岁的“其他”男性,但他们根本没有出现。
编辑:我在代码中添加了代码,展示了我如何在 pandas 中按对象进行分组以及我如何求和以找到每个组中的计数。
最佳答案
使用带有预定义索引和 fill_value=0 的 reindex
ages = np.arange(21, 26)
genders = ['male', 'female']
races = ['white', 'black', 'hispanic', 'asian', 'other']
sim_size = 10000
midx = pd.MultiIndex.from_product([
ages,
genders,
races
], names=['Age', 'Gender', 'Race'])
sim_df = pd.DataFrame({
# I use [1:-1] to explicitly skip some age groups
'Age': np.random.choice(ages[1:-1], sim_size),
'Gender': np.random.choice(genders, sim_size),
'Race': np.random.choice(races, sim_size)
})
这些将缺少年龄组
counts = sim_df.groupby(sim_df.columns.tolist()).size()
counts.unstack()

这填补了缺失的年龄组
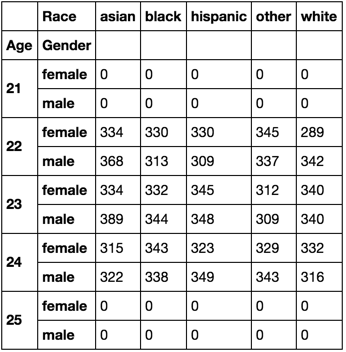
counts.reindex(midx, fill_value=0).unstack()
关于python - Python Pandas 中的 Groupby/Sum - 零计数不显示......有时,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/39308093/