假设以下数据框
>>> import pandas as pd
>>> L = [(1,'A',9,9), (1,'C',8,8), (1,'D',4,5),(2,'H',7,7),(2,'L',5,5)]
>>> df = pd.DataFrame.from_records(L).set_index([0,1])
>>> df
2 3
0 1
1 A 9 9
C 8 8
D 4 5
2 H 7 7
L 5 5
我想过滤multiindex level 1第n个位置的行,即过滤第一个
2 3
0 1
1 A 9 9
2 H 7 7
或者过滤第三个
2 3
0 1
1 D 4 5
我怎样才能做到这一点?
最佳答案
您可以在 GroupBy.nth 的帮助下过滤行在对多索引 DF 的第一级执行分组之后。由于 n 遵循基于 0 的索引方法,您需要为其提供适当的值,如下所示:
1) 选择按 level=0 分组的第一行:
df.groupby(level=0, as_index=False).nth(0)
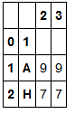
2) 选择按 level=0 分组的第三行:
df.groupby(level=0, as_index=False).nth(2)

关于python - 在具有多索引的 pandas Dataframe 中,我如何按顺序过滤?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/42747987/