下面的代码与 http://docs.python.org/2/library/queue.html 处的 python 官方 Queue 示例几乎相同。
from Queue import Queue
from threading import Thread
from time import time
import sys
num_worker_threads = int(sys.argv[1])
source = xrange(10000)
def do_work(item):
for i in xrange(100000):
pass
def worker():
while True:
item = q.get()
do_work(item)
q.task_done()
q = Queue()
for item in source:
q.put(item)
start = time()
for i in range(num_worker_threads):
t = Thread(target=worker)
t.daemon = True
t.start()
q.join()
end = time()
print(end - start)
这些是 Xeon 12 核处理器上的结果:
$ ./speed.py 1
12.0873839855
$ ./speed.py 2
15.9101941586
$ ./speed.py 4
27.5713479519
我预计增加工作人员的数量会减少响应时间,但实际上它正在增加。我做了一遍又一遍的实验,但结果没有改变。
我是否遗漏了一些明显的东西?或者 python 队列/线程不能正常工作?
最佳答案
是的,关于 GIL,Maxim 是正确的。但是一旦你在 worker 中做了一些值得做的事情,在大多数情况下情况就会改变。在线程中完成的典型事情包括等待 I/O 或其他可以很好地完成线程切换的事情。如果您不只是计算 worker 中的数字,而是模拟在 sleep 中工作,情况会发生巨大变化:
#!/usr/bin/env python
from Queue import Queue
from threading import Thread
from time import time, sleep
import sys
num_worker_threads = int(sys.argv[1])
source = xrange(1000)
def do_work(item):
for i in xrange(10):
sleep(0.001)
def worker():
while True:
item = q.get()
do_work(item)
q.task_done()
q = Queue()
for item in source:
q.put(item)
start = time()
for i in range(num_worker_threads):
t = Thread(target=worker)
t.daemon = True
t.start()
q.join()
end = time()
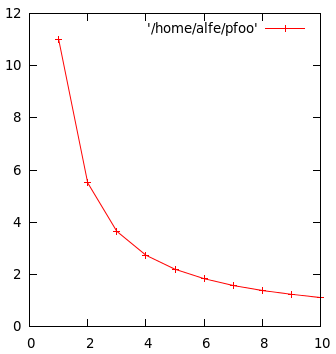
结果如下:
for i in 1 2 3 4 5 6 7 8 9 10; do echo -n "$i "; ./t.py $i; done
1 11.0209097862
2 5.50820493698
3 3.65133094788
4 2.73591113091
5 2.19623804092
6 1.83647704124
7 1.57275605202
8 1.38150596619
9 1.23809313774
10 1.1111137867
关于python - 为什么一个简单的 python 生产者/消费者多线程程序不能通过增加 worker 数量来加速?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/16665367/