在我的 Dataframe 中,我有一个字段显示加类订购的产品的状态。这可以是“新建”、“已取消”、“已填充”或“部分”。我总结了记录的每个订单(Orderid)的模式,并对可能出现的不同模式进行了统计。然而,这导致了超过 1385 种不同的模式。我现在想将这些模式压缩到箱子中,例如,如果订单状态是:新的、新的、取消的、新的、填充的将被压缩为:新的、取消的、新的、填充的。
这将被放入与以下模式相同的容器中:新的、新的、新的、已取消的、已取消的、新的、新的、已填充的。
这是原始数据的样子:
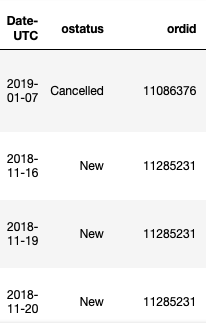
按每个 OrderID 分组后:
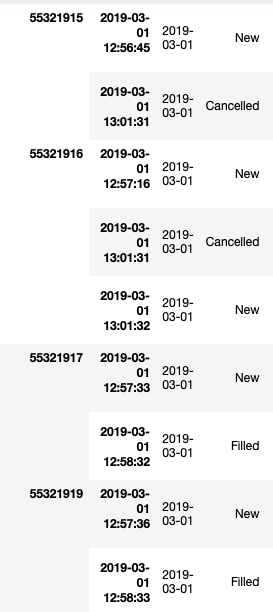
为了查看数据中存在的 OrderStatus 模式,应用了以下代码:
def status_transition_with_timestamp(each_grouped_df):
sorted_df = each_grouped_df.sort_values('timestamp', ascending=True)
concatenated_transition = ','.join(sorted_df['ostatus'])
return concatenated_transition
result = df_grouped['ostatus'].agg(status_transition_with_timestamp)
result.groupby('ostatus').count()
{kind=link}
最佳答案
要删除连续的重复项,请使用 itertools.groupby :
from itertools import groupby
df['ostatus'] = df['ostatus'].apply(lambda x: ','.join([x for x, _ in groupby(x.split(','))]))
然后您将拥有独特的序列,您可以执行聚合。
例子:
df = pd.DataFrame({'Status': ['New,New,Cancelled', 'New,Cancelled', 'Cancelled,New,Cancelled,New']})
df
# Status
#0 New,New,Cancelled
#1 New,Cancelled
#2 Cancelled,New,Cancelled,New
df['Status'] = df['Status'].apply(lambda x: ','.join([x for x, _ in groupby(x.split(','))]))
df
# Status
#0 New,Cancelled
#1 New,Cancelled
#2 Cancelled,New,Cancelled,New
关于python - 如何对重复模式进行分类?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56147052/