简单的问题。当我运行 this通过 pytesser 的图像,我得到 $+s。我该如何解决?
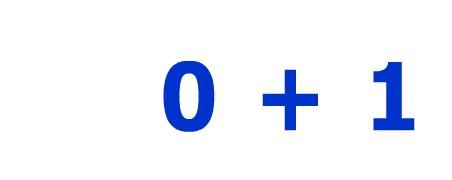{kind=link}
编辑
所以...我的代码生成与上面链接的图像相似的图像,只是数字不同,并且应该解决简单的数学问题,如果我能从图片中得到的只是,这显然是不可能的$+s
这是我目前使用的代码:
from pytesser import *
time.sleep(2)
i = 0
operator = "+"
while i < 100:
time.sleep(.1);
img = ImageGrab.grab((349, 197, 349 + 452, 197 + 180))
equation = image_to_string(img)
然后我将继续解析方程式...一旦我让 pytesser 开始工作。
最佳答案
试试我的小功能。我正在从 svn 存储库运行 tesseract,因此我的结果可能更准确。
我在 Linux 上,所以在 Windows 上,我认为您必须将 tesseract 替换为 tesseract.exe 才能使其正常工作。
import tempfile, subprocess
def ocr(image):
tempFile = tempfile.NamedTemporaryFile(delete = False)
process = subprocess.Popen(['tesseract', image, tempFile.name], stdout = subprocess.PIPE, stdin = subprocess.PIPE, stderr = subprocess.STDOUT)
process.communicate()
handle = open(tempFile.name + '.txt', 'r').read()
return handle
还有一个示例 Python session :
>>> import tempfile, subprocess
>>> def ocr(image):
... tempFile = tempfile.NamedTemporaryFile(delete = False)
... process = subprocess.Popen(['tesseract', image, tempFile.name], stdout = subprocess.PIPE, stdin = subprocess.PIPE, stderr = subprocess.STDOUT)
... process.communicate()
... handle = open(tempFile.name + '.txt', 'r').read()
... return handle
...
>>> print ocr('326_fail.jpg')
0+1
关于python - Pytesser 不准确,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/5925344/