我正在实现一些聚类分析算法,尤其是聚类验证算法。有交叉验证、外部索引、内部索引、相对索引等几种方式。我正在尝试实现内部索引下的算法。
内部索引 - 基于数据的内在内容。它用于在不考虑外部信息的情况下衡量聚类结构的优劣。 我的兴趣是Silhouette系数
s(i) = b(i) - a(i) / max{a(i), b(i)}
为了更清楚,我们假设我有以下多模型分布:
library(mixtools)
wait = faithful$waiting
mixmdl = normalmixEM(wait)
plot(mixmdl,which=2)
lines(density(wait), lty=2, lwd=2)
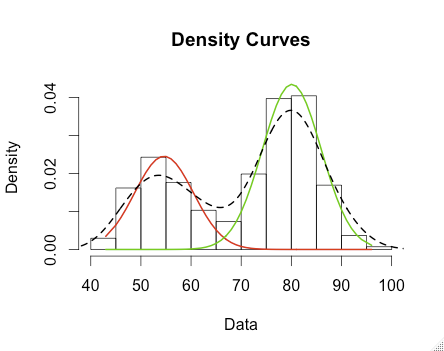
我们看到有两个集群,截止标记在 68 左右。这里没有标签数据,所以没有基本事实来进行交叉验证(无监督)。所以我们需要一种机制来评估集群。在这种情况下,我们从可视化中知道有两个集群,但我们如何清楚地表明两个分布实际上属于集群。基于我在维基百科上的红色剪影给了我们验证。
我想实现一个方法(它实现了 Silhouette),在我的例子中它需要一个 r 值列表,它的等待,在这种情况下的集群数量 2,以及模型,它是模型并返回平均值 s(i) .
我已经开始了,但真的不知道如何前进
Silhouette = function(rList, num_clusters, model) {
}
我的列表摘要如下所示:
Length Class Mode
clust_A 416014 -none- numeric
clust_B 72737 -none- numeric
clust_C 6078 -none- numeric
myList$clust_A 将返回属于该集群的点
[1] 13 880 497 1864 392 55 1130 248 437 37 62 153 60 117
[15] 22 106 71 1026 446 1558 23 56 287 402 46 1506 115 2700
[29] 67 134 48 536 41 506 1098 33 30 280 225 16 25 17
[43] 63 1762 477 174 98 76 157 698 47 312 40 3 198 621
[57] 15 34 226 657 48 110 23 250 14 32 137 272 26 257
[71] 270 133 1734 78 134 8 5 225 187 166 35 15 94 2825
[85] 2 8 94 89 54 91 77 17 106 1397 16 25 16 103
问题是我认为现有的库不接受这种类型的数据结构。
最佳答案
Silhouette 假定所有聚类具有相同的方差。
恕我直言,将此度量与 EM 聚类一起使用没有意义。
关于R实现聚类分析,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/26794071/