我试图在 LL 解析算法的上下文中理解最左边的推导。这link从生成的角度解释它。即它展示了如何遵循最左推导从一组规则中生成特定的标记序列。
但是我在想相反的方向。给定一个标记流和一组语法规则,如何通过最左推导找到应用一组规则的正确步骤?
让我们继续使用上述链接中的以下语法:
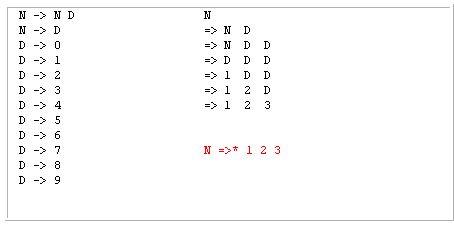
并且给定的标记序列是:1 2 3
一种方法是这样的:
1 2 3
-> D D D
-> N D D (rewrite the *left-most* D to N according to the rule N->D.)
-> N D (rewrite the *left-most* N D to N according to the rule N->N D.)
-> N (same as above.)
但是还有其他方法可以应用语法规则:
1 2 3 -> D D D -> N D D -> N N D -> N N N
或
1 2 3 -> D D D -> N D D -> N N D -> N N
但只有第一个推导以单个非终结符结束。
随着 token 序列长度的增加,可以有更多的方式。我认为要推断出正确的推导步骤,需要两个先决条件:
- 起始/根规则
- token 序列
给出这 2 个后,找到推导步骤的算法是什么?我们是否必须使最终结果成为单个非终结符?
最佳答案
LL解析的一般过程包括重复:
预测堆栈顶部语法符号的产生式(如果该符号是非终结符号),并用产生式的右侧替换该符号。 p>
将堆栈中的顶部语法符号与下一个输入符号匹配,同时丢弃它们。
匹配操作没有问题,但预测可能需要 oracle。但是,出于此解释的目的,只要预测有效,预测的机制就无关紧要了。例如,可能是对于一些小整数 k,k 输入符号的每个可能序列最多只与一个可能的产生式一致,在这种情况下,您可以使用查找表。在那种情况下,我们说文法是LL(k)。但是你可以使用任何机制,包括魔法。只需要预测总是准确的。
在此算法的任何步骤中,部分派(dispatch)生的字符串是附加在堆栈上的消耗输入。最初没有消耗的输入,堆栈仅由开始符号组成,因此部分派(dispatch)生的字符串(应用了 0 次派生)。由于消耗的输入仅由终端组成,并且算法只会修改堆栈的顶部(第一个)元素,因此很明显,部分派(dispatch)生的字符串系列构成了最左边的派生。
如果解析成功,整个输入将被消耗并且堆栈将为空,因此解析结果是从起始符号开始的输入的最左边推导。
这是您示例的完整解析:
Consumed Unconsumed Partial Production
Input Stack input derivation or other action
-------- ----- ---------- ---------- ---------------
N 1 2 3 N N → N D
N D 1 2 3 N D N → N D
N D D 1 2 3 N D D N → D
D D D 1 2 3 D D D D → 1
1 D D 1 2 3 1 D D -- match --
1 D D 2 3 1 D D D → 2
1 2 D 2 3 1 2 D -- match --
1 2 D 3 1 2 D D → 3
1 2 3 3 1 2 3 -- match --
1 2 3 -- -- 1 2 3 -- success --
如果您阅读最后两列,您可以看到从 N 开始到 1 2 3 结束的推导过程。在此示例中,只能使用魔法进行预测,因为规则 N → N D 对于任何 k 都不是 LL(k);使用右递归规则 N → D N 将允许 LL(2) 决策过程(例如,“如果至少有两个未使用的输入,则使用 N → D N token ;否则 N → D".)
您尝试生成的以 1 2 3 开头并以 N 结尾的图表是一个自下而上 解析。使用 LR 算法的自底向上解析对应于最右推导,但推导需要向后读取,因为它以开始符号结束。
关于algorithm - 说明 token 流上的最左边的推导,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/41531642/