我正在尝试为以下语法创建一个 LALR(1) 解析器并发现一些移位/归约冲突。
S := expr
expr := lval | ID '[' expr ']' OF expr
lval := ID | lval '[' expr ']'
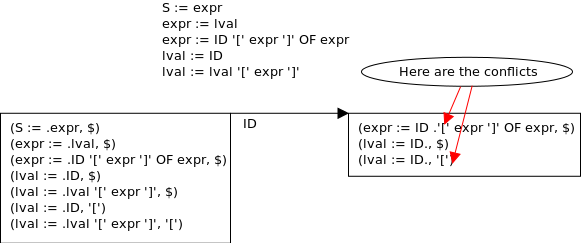
所以解析器无法正确解析字符串“ID[ID]”。 我的问题是,
- 是否有任何通用方法可以将此类非 LALR(1) 文法转换为 LALR(1) 文法?
- 如果两个文法生成完全相同的语言,并且我们知道一个不是 LALR(1),那么我们能否知道另一个是否是 LALR(1)?
上面提到的语法只是一个例子,我真正想知道的是解决这些语法问题的一般方法。欢迎任何建议或阅读建议。
提前致谢。
最佳答案
1 . Are there any general ways to convert such non-LALR(1) grammars into LALR(1) grammars?
没有。将任意上下文无关文法 (CFG) 转换为 LALR(1) 文法可能可行,也可能不可行。此外,如果你有一个 CFG 和一个 LALR(1) 文法,你无法判断它们是否识别相同的语言。 (更糟糕的是,没有算法甚至可以告诉您任意 CFG 是否识别其字母表的每个可能字符串。)
2 . If two grammars generate exactly the same languages and we know that one is not LALR(1), can we know if the other is LALR(1)?
同样,不。如上所述,没有算法可以验证两个文法生成相同的语言,但即使假设您知道两个文法生成相同的语言,其中一个不是 LALR(1) 这一事实也不会告诉您关于另一个的任何信息一个。
但是,有一个有用的结果。如果你有一个有限 k > 1 的 LALR(k) 文法,那么你可以生成一个 LALR(1) 文法。换句话说,对于 k > 1,不存在 LALR(k) 语言;如果一种语言具有 LALR(k) 文法,则对于满足 1 ≤ k' < k 的任何 k',它都具有 LALR(k') 文法。
但是,这对您的语法没有帮助,因为无法通过增加对任何有限值的前瞻性来消除冲突。
不过,有一种简单的方法可以消除这种特定的 shift-reduce 冲突,而且这种方法经常有效。考虑两个相互冲突的规则:
lval := lval '[' expr ']'
expr := ID '[' expr ']' OF expr
问题是在第一种情况下,ID 必须立即缩减为 lval(或者至少,在以下 expr 被缩减之前)减少),但在第二种情况下,它可能不会减少到 lval。但是在我们减少 expr 并遇到(或没有)OF 之前,我们无法判断我们处于哪种情况。
如果我们可以在不进行内部 lval 缩减的情况下完成 lval 的产生,那么我们就不会有问题,因为实际的缩减会在 token 跟随时发生] 可见。
这可能有一个技术术语,但我不知道。我一直把它描述为“递减延迟”,在很多情况下它并不是很难:
lval' := ID `[` expr `]`
| lval' `[` expr `]`
lval := ID
| lval'
expr := lval
| ID '[' expr ']' OF expr
关于algorithm - 有没有一种通用的方法可以将明确的上下文无关文法转换为 LALR(1) 文法?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/18498722/