问题:
1.) 我有一个形状文件,如下所示:

坐标的极值是:xmin = 300,000 , xmax = 620,000 , ymin = 31,000和ymax = 190,000 .
2.) 我有大约数据集。 2mio 点(每个点都在给定的多边形内) - 每个点都属于 5 个不同类别之一。
现在,对于边界内的每个点(点之间的距离必须为 10 ,这样我们就会得到 580,800,000 点),我想根据数据集中最近点的类别来确定颜色。
最后我想画一个ggplot ,其中每个点的颜色取决于其类别(因此我将使用 5 不同的颜色)。
到目前为止我所拥有的:
我的解决方案想法尚未优化,并且需要 R 永远来确定多边形内每个点的类别。
1.) 我创建了一个新的数据集,其中的点呈矩形形状,具有坐标极值,其中 10点之间的单位。从新数据集中,我选择了落在多边形边界内的点(使用包 pnt.in.poly 中的函数 SDMTools )。然后我想找到多边形中每个点的最近点(来自数据集)并确定类别,但我从未设法从 580,800,000 获取子集点(显然)。
2.) 我尝试取 2mio 点并根据它们的类别对它们周围的区域进行着色,但这不起作用。
我知道不可能绘制这么多点并查看与200,000,000绘图之间的差异点和图 1,000,000点,但我希望在仅缩放(绘制)多边形中的一个小点(例如 100 x 100 的大小)时获得准确的着色。
问题:有没有更好的方法为多边形中的这么多点着色(通过创建新的形状文件或对点进行分组)?
感谢您的想法!
最佳答案
如果您在问题中包含一些数据,即使(特别是)它是一个玩具数据集,这确实很有帮助。正如你不知道的那样,我做了一个玩具示例。首先,我定义一个简单的形状数据框和一个合成数据的数据框,其中包括 x、y 和 grp(即分类数据)具有 5 个级别的变量)。我将后者裁剪为前者并绘制结果,
# Dummy shape function
df_shape <- data.frame(x = c(0, 0.5, 1, 0.5, 0),
y = c(0, 0.2, 1, 0.8, 0))
# Load library
library(ggplot2)
library(sgeostat) # For in.polygon function
# Data frame of synthetic data: random [x, y] and category (grp)
df_synth <- data.frame(x = runif(500),
y = runif(500),
grp = factor(sample(1:5, 500, replace = TRUE)))
# Remove points outside polygon
df_synth <- df_synth[in.polygon(df_synth$x, df_synth$y, df_shape$x, df_shape$y), ]
# Plot shape and synthetic data
g <- ggplot(df_shape, aes(x = x, y = y)) + geom_path(colour = "#FF3300", size = 1.5)
g <- g + ggthemes::theme_clean()
g <- g + geom_point(data = df_synth, aes(x = x, y = y, colour = grp))
g
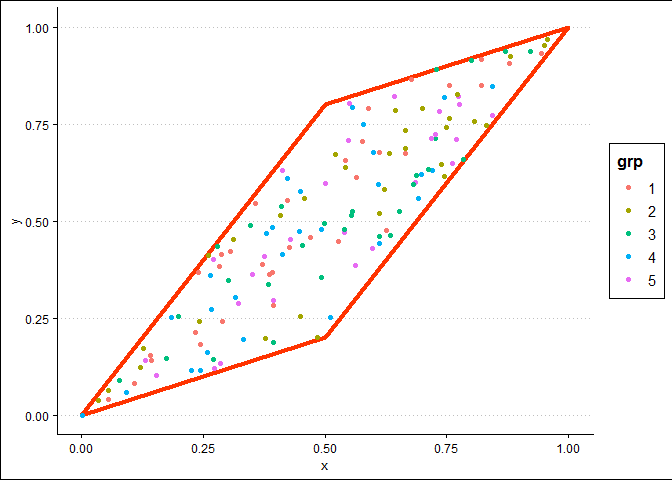
接下来,我创建一个规则网格并使用多边形进行裁剪。
# Create a grid
df_grid <- expand.grid(x = seq(0, 1, length.out = 50),
y = seq(0, 1, length.out = 50))
# Check if grid points are in polygon
df_grid <- df_grid[in.polygon(df_grid$x, df_grid$y, df_shape$x, df_shape$y), ]
# Plot shape and show points are inside
g <- ggplot(df_shape, aes(x = x, y = y)) + geom_path(colour = "#FF3300", size = 1.5)
g <- g + ggthemes::theme_clean()
g <- g + geom_point(data = df_grid, aes(x = x, y = y))
g
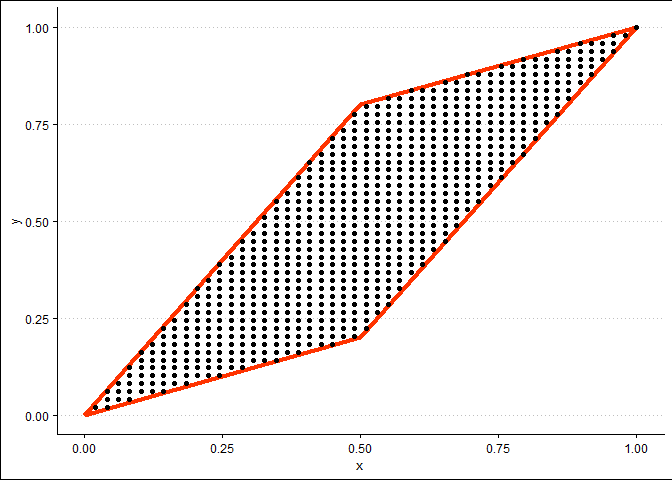
为了通过合成数据集中最近的点对该网格上的每个点进行分类,我使用 knn 或 k-nearest-neighbours,其中 k = 1。这给出了类似的结果。
# Classify grid points according to synthetic data set using k-nearest neighbour
df_grid$grp <- class::knn(df_synth[, 1:2], df_grid, df_synth[, 3])
# Show categorised points
g <- ggplot()
g <- g + ggthemes::theme_clean()
g <- g + geom_point(data = df_grid, aes(x = x, y = y, colour = grp))
g
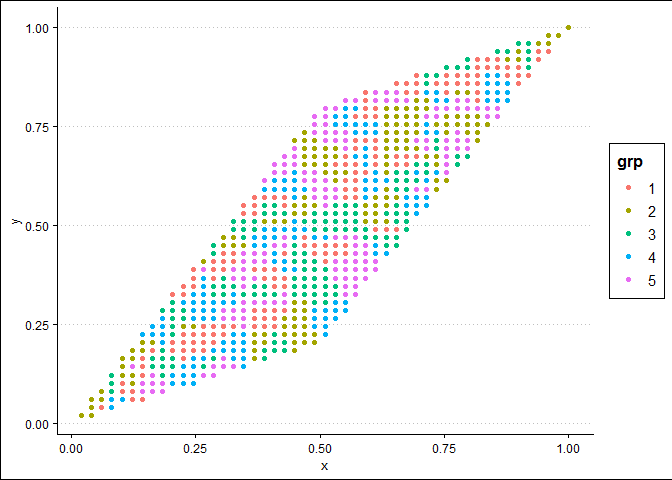
所以,这就是我如何解决您关于网格上的点分类问题的部分。
您问题的另一部分似乎与解决方案有关。如果我理解正确,即使放大,您也希望获得相同的分辨率。此外,您不想在缩小时绘制这么多点,因为您甚至看不到它们。在这里,我创建了一个绘图函数,可让您指定分辨率。首先,我绘制形状中的所有点,每个方向 50 个点。然后,我绘制一个子区域(即缩放),但在每个方向上保持相同数量的点数,以便它在点数方面看起来与之前的绘图几乎相同。
res_plot <- function(xlim, xn, ylim, yn, df_data, df_sh){
# Create a grid
df_gr <- expand.grid(x = seq(xlim[1], xlim[2], length.out = xn),
y = seq(ylim[1], ylim[2], length.out = yn))
# Check if grid points are in polygon
df_gr <- df_gr[in.polygon(df_gr$x, df_gr$y, df_sh$x, df_sh$y), ]
# Classify grid points according to synthetic data set using k-nearest neighbour
df_gr$grp <- class::knn(df_data[, 1:2], df_gr, df_data[, 3])
g <- ggplot()
g <- g + ggthemes::theme_clean()
g <- g + geom_point(data = df_gr, aes(x = x, y = y, colour = grp))
g <- g + xlim(xlim) + ylim(ylim)
g
}
# Example plot
res_plot(c(0, 1), 50, c(0, 1), 50, df_synth, df_shape)
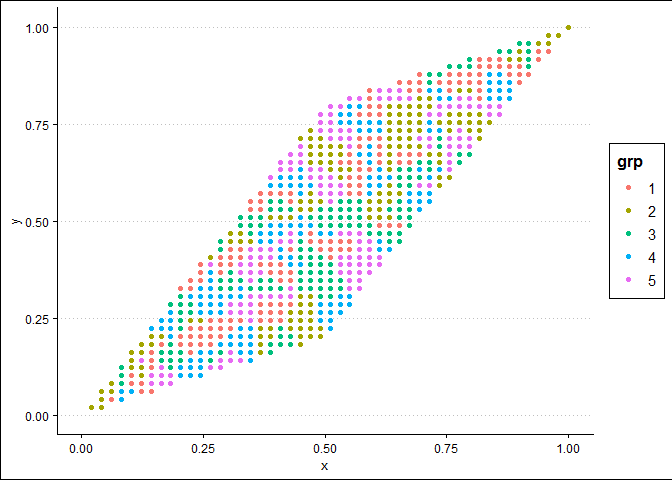
# Same resolution, but different limits
res_plot(c(0.25, 0.75), 50, c(0, 1), 50, df_synth, df_shape)
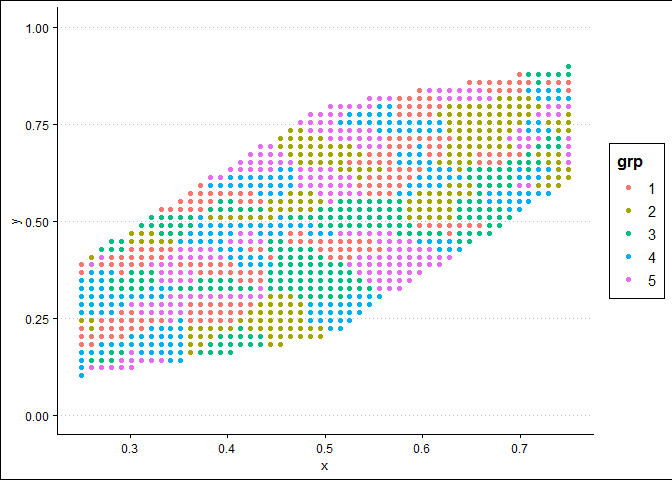
由 reprex package 于 2019-05-31 创建(v0.3.0)
希望这能解决您的问题。
关于r - 根据 R 中的另一个点数据集为多边形中的每个点着色,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56394555/