我想在我的博客上做一些类似于 gmail 的“考虑包含”建议的事情,但带有标签。
我正在考虑存储这样的标签集:
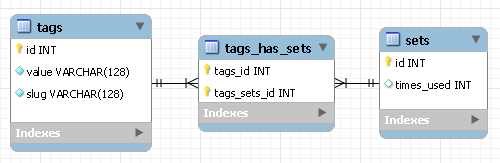
我想到了以下算法:
//a blog post is published
//it has the tags "A", "B" & "C" :
if the tag set "A,B,C" doesn't exist
create it
else
add 1 to "number of times used"
并且建议标签:
//a blog post is being written.
//the author includes the tags "A" and "C"
//which tags should I suggest ?
find all the tags sets that contain "A" and "C"
among them, find the one with the highest "number of times used"
suggest the tags of the set not already picked (A & C)
有更好/更聪明的方法来完成这项任务吗?数据库模型怎么样?我可以对其进行优化,以便像“包含 A 和 C 的集合”这样的搜索不会太慢吗?
最佳答案
搜索模型问题:
您的模型对我来说似乎有点过于简化,因为非常频繁的标签很可能始终是建议的标签,即使有与 A,C 对更相关的标签。
您可能应该考虑 tf-idf模型,如果罕见术语也连接到“查询”[这里的查询是 A 和 B],那么它会增强罕见术语,因为如果罕见术语通常与 一起使用A 和 B - 可能与它们非常相关。
这个想法很简单:如果一个标签经常与 A 和 B 一起使用 - 那就加强它。 [tf]
此外,如果某个术语很罕见[此标签的总使用次数] - 给予它一个提升[idf]
每个标签的“分数”将是 tf-idf 分数的总和
性能问题:
您可能还考虑为此任务创建一个 inverted index - 加快搜索速度。
如果您使用的是java,apache lucene是一个成熟的库,可以帮助您。
关于algorithm - Gmail中的 "Consider including"功能是如何实现的?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/9277683/