我正在通过比较 interactivepython.org 提供的变位词算法来研究数量级.我正在使用 IPython 的 %timeit 魔法来测试这些函数。解决方法如下。第一种算法:
# Sort and Compare
def anagram_solution2(s1,s2):
a_list1 = list(s1)
a_list2 = list(s2)
a_list1.sort()
a_list2.sort()
pos = 0
matches = True
while pos < len(s1) and matches:
if a_list1[pos] == a_list2[pos]:
pos = pos + 1
else:
matches = False
return matches
第二个算法:
# Count and Compare
def anagram_solution4(s1, s2):
c1 = [0] * 26
c2 = [0] * 26
for i in range(len(s1)):
pos = ord(s1[i]) - ord('a')
c1[pos] = c1[pos] + 1
for i in range(len(s2)):
pos = ord(s2[i]) - ord('a')
c2[pos] = c2[pos] + 1
j = 0
still_ok = True
while j < 26 and still_ok:
if c1[j] == c2[j]:
j = j + 1
else:
still_ok = False
return still_ok
排序和比较 函数(解决方案 2)被声明为高阶,O(n^2) 或 O(nlogn) 解决方案。 计数和比较 函数(解决方案 4)被描述为 O(n) 解决方案,因此如果使用 %timeit 进行测试,我预计时间会更短。但是,我得到以下结果:
%timeit anagram_solution2('conversationalists', 'conservationalists')
# 100000 loops, best of 3: 13 µs per loop
%timeit anagram_solution4('conversationalists', 'conservationalists')
# 10000 loops, best of 3: 21 µs per loop
也许我遗漏了一些基本的东西,但为什么线性解决方案比二次/对数线性解决方案花费的时间更长?
编辑
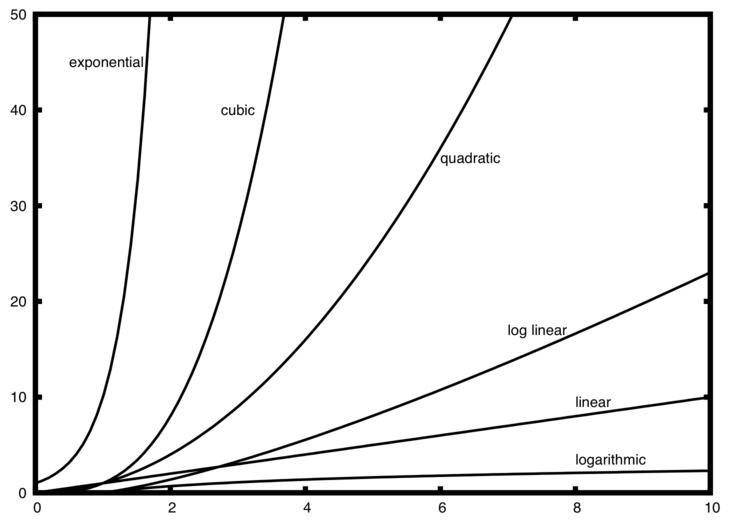
为了完整起见,我包括了 common Big-O functions 的图表.在较低的“x”值处,对数线性曲线和线性曲线似乎有交点。
最佳答案
请记住,O() 表示法仅是整个时间等式的主导项。例如,O(n) 可能指的是一个需要 1000*n + 7000 秒的过程;竞争的 O(n^2) 过程可能是 0.5*n^2 + .10 秒。 N 必须非常大,n^2 进程才能在更短的时间内运行。
在这种情况下,O(n) 算法会经历三个单独的 n 长度循环,并插入一些操作。这会使 N 值较小时速度变慢。我将运行几个测试...
我用两个字母尝试了这个,然后是字母表的一个副本,然后是 30 个副本:
length 2 O(n^2) 1.00135803223e-05 O(n) 1.50203704834e-05
length 26 O(n^2) 1.69277191162e-05 O(n) 2.59876251221e-05
length 780 O(n^2) 0.000540971755981 O(n) 0.00049901008606
在我的环境中,O(n) 算法直到 500 个字符才 catch ,但从那时起它将是更快的算法。
关于python - 为什么 IPython `%timeit` 会为 O(n) 解决方案产生更慢的时间?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/33270174/