我正在尝试完全理解 Differential Synchronization algorithm尤其是保证交付方法(第 4 节)。
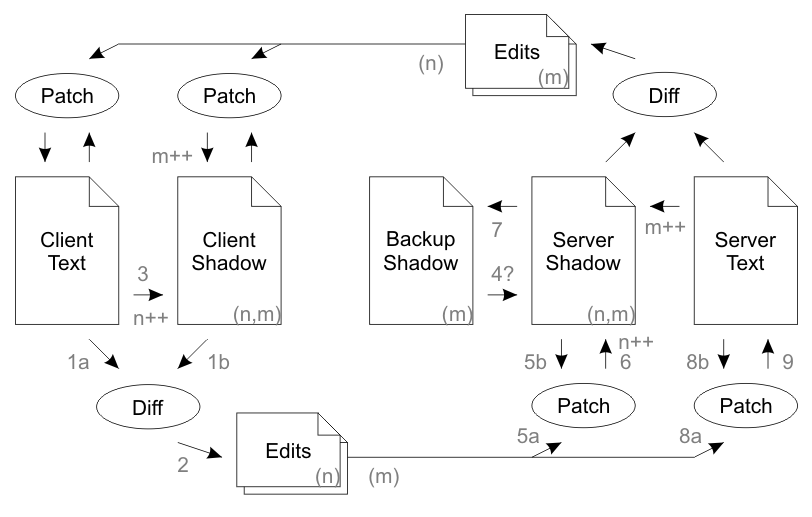
我不明白为什么在同步周期的上半部分需要编辑堆栈。
编辑堆栈的用途如下(从第 4 节的第二段复制):
[...] in the case of packet loss, the edits are queued up in a stack and are retransmitted to the remote party on every sync until the remote party returns an acknowledgment of receipt.
这是有道理的。但在第六段的后面(丢失返回数据包案例)它说:
This indicates that the previous response must have been lost. Therefore the server deletes its edit stack and copies the Backup Shadow into Shadow Text (step 4).
所以,据我了解:
在正常操作期间:编辑堆栈(在上半部分)将包含一个条目,该条目在下一个同步周期中被确认并删除。
如果出现网络错误:客户端无法确认编辑堆栈,然后服务器将简单地清除它。
如果这是正确的,那么上半部分的编辑堆栈将是空的或包含一个条目。此外,在任何情况下,该单一条目都不会(重新)发送回客户。让它完全没用?!
那么显而易见的问题是,为什么我们需要一个编辑堆栈(在上半部分)?
我确信我遗漏了一些重要的东西。请帮帮我。
最佳答案
您的观点适用于客户端-服务器 架构。服务器的 Edits 堆栈是更通用的对称表示的保留,其中客户端和服务器具有相同的功能和结构(特别是,任何一方都可以发起通信)。虽然客户端的 Backup Shadow 最好在客户端-服务器设置中删除以节省空间/时间,但 Edits 仍然可以使用堆栈数据结构而没有任何缺点,并且一致的 API 的好处。请注意,该算法大约可追溯到 2009 年。今天(2017 年),您可能会选择使用 WebSockets 或 WebRTC。差分同步算法预期并适应这样一种设置,其中双方本质上是对等并遵循相同的协议(protocol)。
关于algorithm - 了解 Neil Fraser 的差分同步算法,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/29489409/