假设您有一本包含有效单词的字典。
给定一个已删除所有空格的输入字符串,确定该字符串是否由有效单词组成。
您可以假设字典是一个提供 O(1) 查找的哈希表。
Some examples:
helloworld-> hello world (valid)
isitniceinhere-> is it nice in here (valid)
zxyy-> invalid
如果一个字符串有多种可能的解析,只返回true即可。
字符串可以很长。因此,请考虑一种空间和时间效率都很高的算法。
最佳答案
我认为作为有效单词(从有限字典中提取的单词)的串联出现的所有字符串的集合形成了字符字母表上的常规语言。然后,您可以构建一个有限自动机,它可以准确地接受您想要的字符串;计算时间为 O(n)。
例如,让字典包含单词{bat, bag}。然后我们构造以下自动机:状态由 0、1、2 表示。边:(0,1,b)、(1,2,a)、(2,0,t)、(2,0,g) ;其中三元组 (x,y,z) 表示输入 z 上从 x 到 y 的边。唯一接受状态是 0。在每一步中,在读取下一个输入符号时,您必须计算在该输入上可达的状态集。鉴于自动机中的状态数是常数,这具有 O(n) 的复杂性。至于空间复杂度,我认为你可以使用上面构造提示的 O(number of words) 来完成。
再举一个例子,使用单词 {bag, bat, bun, but} 自动机看起来像这样: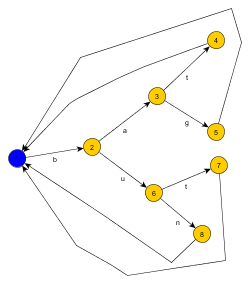
假设已经构建了自动机(执行此操作的时间与单词的长度和数量有关:-)我们现在认为,决定自动机是否接受字符串的时间为 O( n) 其中 n 是输入字符串的长度。 更正式地说,我们的算法如下:
- 设 S 是一组状态,最初包含起始状态。
- 读取下一个输入字符,我们用a表示。
- 对于 S 中的每个元素 s,确定我们在读取 a 时从 s 进入的状态;也就是说,状态 r 使得上面的符号 (s,r,a) 是一条边。让我们用 R 表示这些状态的集合。也就是说,R = {r | S中的s,(s,r,a)是一条边}。
- (如果 R 为空,则不接受该字符串,算法停止。)
- 如果没有更多的输入符号,检查是否有任何接受状态在 R 中。(在我们的例子中,只有一个接受状态,即起始状态。)如果是,则字符串被接受,如果不是,不接受该字符串。
- 否则,取 S := R 并转到 2。
现在,这个循环的执行次数与输入符号的数目一样多。我们唯一需要检查的是第 3 步和第 5 步需要常数时间。鉴于 S 和 R 的大小不大于自动机中状态的数量,这是恒定的,并且我们可以以查找时间恒定的方式存储边缘,因此如下所示。 (请注意,我们当然会丢失多个“解析”,但这也不是必需的。) 我认为这实际上称为常规语言的成员资格问题,但我找不到合适的在线引用。
关于algorithm - 标记长字符串中的有效单词,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/3553958/