让我们来看一个非常简单的 jmeter 脚本,它在 HTTP 请求 (GET) 中下载一个 128MB 的文件。目的是强调被测服务器,因此没有必要将文件存储在本地或 jvm 的内存中以供将来使用。该文件应该已完全下载,因为它与服务器保持连接。
场景: 10 个或更多线程以 5 秒的间隔同时运行。假设网络带宽不受限制。
文件位置:https://storage.googleapis.com/videos12/dummy.txt
问题是 - 你会为 jmeter 的 jvm 的堆大小设置多少内存,这样你就不会出现 java OOM 错误?进行基本计算的方法是什么?
set HEAP=-Xms512m -Xmx512m --> 这个可以在jmeter.bat文件中设置。
最佳答案
- 快速回答:512 Mb 对于 10 个线程下载 128Mb 的文件来说太低了。将堆增加到总物理可用 RAM 的 80%。
- 更长的答案:阅读关于 Java Performance Tuning, Profiling, and Memory Management 的 Material ,辞掉你的测试员工作,成为 JVM 专家。
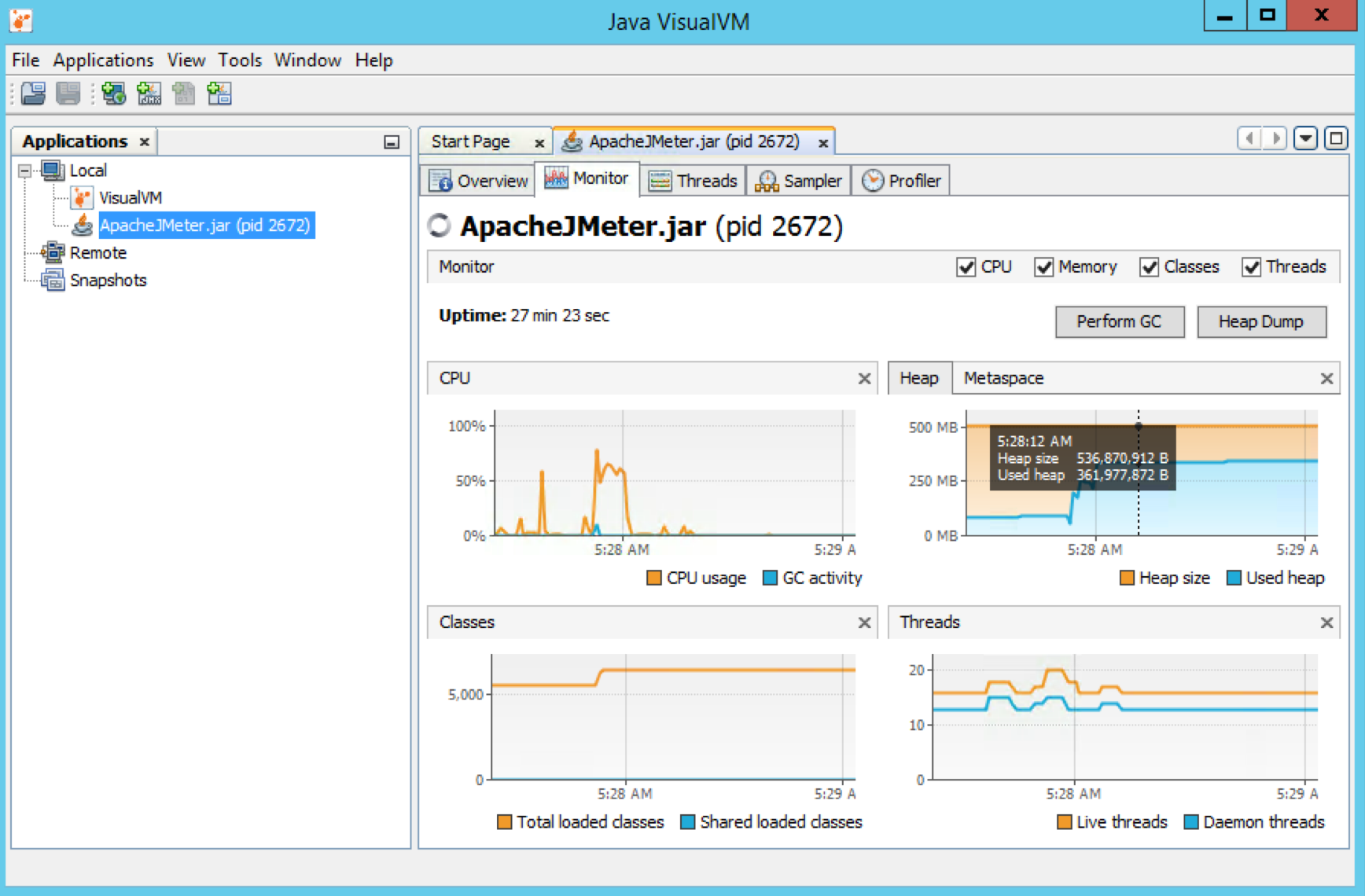
好的答案:不要问也不要猜,要测量。使用即 JVisualVM :
- 使用 1 个虚拟用户运行测试。测量使用的堆
- 使用 2 个虚拟用户运行测试。测量使用的堆。
- 使用 4 个虚拟用户运行测试。测量使用的堆。
- 进行复杂的算术计算
根据结果设置 JMeter 堆
正确答案:鉴于您丝毫不关心响应,请不要使用 HTTP 请求采样器并使用 JSR223 Sampler反而。示例代码:
import org.apache.http.HttpEntity; import org.apache.http.HttpResponse; import org.apache.http.client.HttpClient; import org.apache.http.client.methods.HttpGet; import org.apache.http.impl.client.HttpClientBuilder; import org.apache.http.util.EntityUtils; HttpClient client = HttpClientBuilder.create().build(); HttpGet get = new HttpGet("https://storage.googleapis.com/videos12/dummy.txt"); HttpResponse response = client.execute(get); SampleResult.setResponseCode(String.valueOf(response.getStatusLine().getStatusCode())); SampleResult.setResponseMessage(response.getStatusLine().getReasonPhrase()); HttpEntity entity = response.getEntity(); SampleResult.setBodySize(Math.round(entity.getContentLength())); EntityUtils.consume(entity);非常重要的一点:
- 确保在“语言:下拉列表”中选择
groovy - 确保勾选
Cache compiled script if available框 - 确保您不要忘记
EntityUtils.consume(entity);行 - 它可以发挥所有作用
- 确保在“语言:下拉列表”中选择
为了更好地理解“正确答案”,请参阅 HttpClient Tutorial Apache HTTP 组件 API 解释和 Beanshell vs JSR223 vs Java JMeter Scripting: The Performance-Off You've Been Waiting For!编写脚本最佳实践的文章。
关于java - JMeter中需要设置多少内存(heap size),我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/40666940/