长话短说
我有一张表, 这个月有大约 200 万次 WRITE 和 0 次 READ。每个月的第一天,我需要读取上个月写入的所有行并生成 CSV + 统计信息。
在这种情况下如何使用 DynamoDB?如何选择READ吞吐量?
详细说明
我有一个记录客户端请求的应用程序。它有大约200个客户。客户需要在每个月的第一天收到一个 CSV,其中包含他们提出的所有请求。他们还需要收费,为此我们需要根据他们提出的请求计算一些统计数据,按请求类型分组。
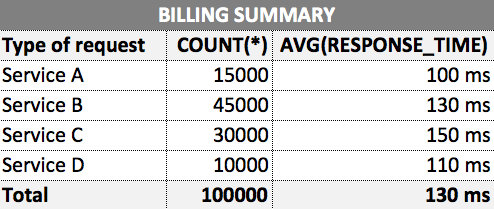
所以在月底,客户会收到如下报告:
我已经找到了两个解决方案,但我仍然相信其中任何一个。
第一个解决方案:好的,每个月的最后一天我都会增加 READ 吞吐量容量,然后运行 map reduce 作业。工作完成后,我将容量降低回原始值。
缺点:不是完全自动化,作业开始时 DynamoDB 容量不可用的风险。
第二个解决方案:我可以将 CSV 和统计数据的生成分解为每天或每小时的小工作。我可以将部分 CSV 存储在 S3 上,并且在每个月的第一天我可以加入这些文件并生成一个新文件。生成统计数据会容易得多,只需从每天/每小时的统计数据中得出一些计算。
缺点:我觉得我正在把一些简单的东西变成复杂的东西。
你有更好的解决方案吗?如果不是,您会选择什么解决方案?为什么?
最佳答案
我自己之前也曾在类似的地方使用过,现在推荐给你,来处理原始数据:
- 尽可能频繁(从每天开始)
- 尽可能接近所需报告输出的格式
- 尽可能多地完成计算/CPU 密集型工作
在报告时间尽可能少做。
这种方法是完全可扩展的——增量频率可以是:
- 根据需要缩小到尽可能小的窗口
- 如果需要则并行
它还可以根据需要重新运行过去几个月的报告,因为报告生成时间应该非常短。
在我的示例中,我每小时将非规范化、预处理(财务计算)数据发送到数据仓库,然后报告只涉及一个非常基本(且快速)的 SQL 查询。
这有一个额外的好处,即可以将生产数据库服务器上的负载分散到许多小块上,而不是每周一次在开票时使其崩溃(每周生产 30000 个开票)。
关于database - 发电机 : How to distribute workload over the month?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/27348604/