我所在的团队正在为我们的公共(public)网站构建新的内容管理系统。我正在尝试找到构建修订控制 机制的最简单和最好的方法。对象模型非常基础。我们有一个抽象的 BaseArticle 类,其中包含版本独立/元数据的属性,例如 Heading 和 CreatedBy。许多类继承自此,例如 DocumentArticle,它具有属性 URL,它将成为文件的路径。 WebArticle 也继承自 BaseArticle 并包括 FurtherInfo 属性和一组 Tabs 对象,其中包括 Body 将保存要显示的 HTML(Tab 对象不派生自任何东西)。 NewsArticle 和 JobArticle 继承自 WebArticle。我们还有其他派生类,但这些提供了足够的示例。
我们为版本控制提出了两种持久化方法。我将它们称为 Approach1 和 Approach2。我使用 SQL Server 为每一个做了一个基本图表:

- 对于 Approach1,计划是通过数据库 Update 保留新版本的
Articles。将为更新设置触发器并将旧数据插入到xxx_Versions表中。我认为需要在每个表上配置触发器。这种方法确实有一个优点,即每篇文章的唯一head版本保存在主表中,旧版本被分割开来。这使得将文章的头版本从开发/暂存数据库复制到 Live 变得容易。 - 使用方法2,计划将新版本的
文章插入到数据库中。文章的头部版本将通过 View 来识别。这似乎具有更少的表和更少的代码(例如,不是触发器)的优势。
请注意,对于这两种方法,计划都是为映射到相关对象的表调用 Upsert 存储过程(我们必须记住要处理添加新文章的情况)。此 upsert 存储过程将为它派生的类调用它,例如upsert_NewsArticle 会调用 upsert_WebArticle 等
我们使用的是 SQL Server 2005,尽管我认为这个问题与数据库风格无关。我对互联网进行了广泛的拖网搜索,并找到了对这两种方法的引用。但我还没有发现任何可以比较两者并显示其中一个更好的东西。我认为,对于世界上所有的数据库书籍,这种方法选择以前一定出现过。
我的问题是:哪些方法最好,为什么?
最佳答案
我的实现可能有点复杂。
首先,您只有一个表来处理所有事情,以便仅在一个点上保持模型设计和数据完整性。
这是基本思想,如果需要,您可以使用 created_by 和 updated_by 列扩展设计。
在MySQL上实现
下面的实现是针对 MySQL 的,但这个想法也可以在其他类型的 SQL 数据库上实现。
表格
DROP TABLE IF EXISTS `myTable`;
CREATE TABLE `myTable` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Primary Key',
`version` int(11) NOT NULL DEFAULT 0 COMMENT 'Version',
`title` varchar(32) NOT NULL COMMENT 'Title',
`description` varchar(1024) DEFAULT NULL COMMENT 'Description',
`deleted_at` datetime DEFAULT NULL COMMENT 'Record deleted at',
`created_at` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'Record created at'
) ENGINE=InnoDB DEFAULT CHARSET=latin1;
ALTER TABLE `myTable`
ADD PRIMARY KEY (`id`, `version`) USING BTREE,
ADD KEY `i_title` (`title`);
- 记录 ID 由
id和version定义。 - 使用
deleted_at,此模型支持软删除 功能。
观看次数
获取当前版本
获取当前记录版本:
CREATE OR REPLACE VIEW vMyTableCurrentVersion AS
SELECT
`id`
, MAX(`version`) AS `version`
, MIN(`created_at`) AS `created_at`
FROM `myTable`
GROUP BY `id`;
获取所有记录(包括删除的记录)
获取所有记录,包括软删除记录:
CREATE OR REPLACE VIEW vMyTableAll AS
SELECT
T.id
, T.version
, T.title
, T.description
, T.deleted_at
, _T.created_at
, T.created_at AS `updated_at`
FROM
`myTable` AS T
INNER JOIN vMyTableCurrentVersion AS _T ON
T.id = _T.id
AND T.version = _T.version;
获取记录
获取记录,从结果中删除软删除记录。
CREATE OR REPLACE VIEW vMyTable AS
SELECT *
FROM `vMyTableAll`
WHERE `deleted_at` IS NULL;
触发器和验证
对于这个例子,我将实现一个唯一的title验证:
DROP PROCEDURE IF EXISTS myTable_uk_title;
DROP TRIGGER IF EXISTS myTable_insert_uk_title;
DROP TRIGGER IF EXISTS myTable_update_uk_title;
DELIMITER //
CREATE PROCEDURE myTable_uk_title(id INT, title VARCHAR(32)) BEGIN
IF (
SELECT COUNT(*)
FROM vMyTable AS T
WHERE
T.id <> id
AND T.title = title
) > 0 THEN
SIGNAL SQLSTATE '45000'
SET MESSAGE_TEXT = 'Duplicated "title"', MYSQL_ERRNO = 1000;
END IF;
END //
CREATE TRIGGER myTable_insert_uk_title BEFORE INSERT ON myTable
FOR EACH ROW
BEGIN
CALL myTable_uk_title(NEW.id, NEW.title);
END //
CREATE TRIGGER myTable_update_uk_title BEFORE UPDATE ON myTable
FOR EACH ROW
BEGIN
CALL myTable_uk_title(NEW.id, NEW.title);
END //
DELIMITER ;
使用示例
选择
SELECT * FROM `vMyTable`;

选择已删除的记录
SELECT * FROM `vMyTableAll`;
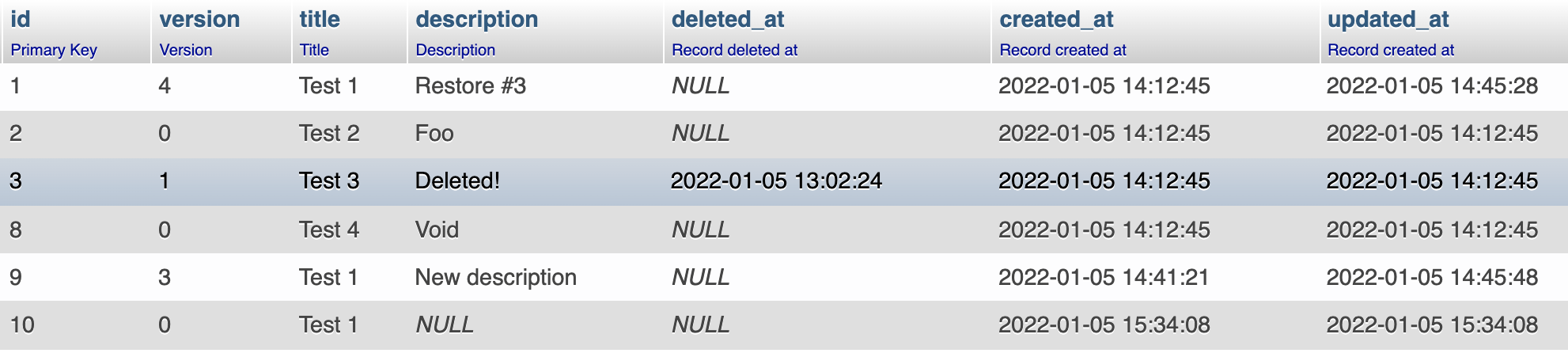
插入/添加/新建
INSERT INTO myTable (`title`) VALUES ('Test 1');
更新/编辑
更新操作应该使用以下代码来完成,而不是 UPDATE ...:
INSERT INTO myTable (`id`, `version`, `title`, `description`)
SELECT
`id`
, `version` + 1 as `version` -- New version
, `title`
, 'New description' AS `description`
FROM `vMyTable`
WHERE id = 1;
软删除
软删除 操作是历史记录中的另一点:
INSERT INTO myTable (`id`, `version`, `title`, `description`, `deleted_at`)
SELECT
`id`
, `version` + 1 as `version` -- New version
, `title`
, `description`
, NOW() AS `deleted_at`
FROM `vMyTable`
WHERE id = 1;
恢复软删除记录
INSERT INTO myTable (`id`, `version`, `title`, `description`, `deleted_at`)
SELECT
`id`
, `version` + 1 as `version` -- New version
, `title`
, `description`
, null AS `deleted_at`
FROM `vMyTableAll` -- Get with deleted
WHERE id = 1;
删除记录&历史
要删除相关的历史记录:
DELETE FROM `myTable` WHERE id = 1;
记录历史
SELECT *
FROM `myTable`
WHERE id = 1
ORDER BY `version` DESC;

缺点
- Unique key constrain 是不可能的,但您可以创建一个触发器来处理它。
- 更新许多记录(
UPDATE ...)如果您想保存历史是不可能的。 - 同时删除多条记录(
DELETE ...)如果您想保存历史记录是不可能的。
引用文献
关于sql - 如何设计具有修订历史的数据库?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/7465225/