使用 iTextSharp 将 html 转换为 pdf
public static MemoryStream CreatePdfFromHtml(
string html, List<Attachment> attachments)
{
MemoryStream msOutput = new MemoryStream();
using (TextReader reader = new StringReader(html))
using (Document document = new Document())
{
PdfWriter writer = PdfWriter.GetInstance(document, msOutput);
document.Open();
foreach (var a in attachments)
{
var image = iTextSharp.text.Image.GetInstance(a.File);
document.Add(image);
}
XMLWorkerHelper.GetInstance().ParseXHtml(writer, document, reader);
writer.CloseStream = false;
document.Close();
msOutput.Position = 0;
return msOutput;
}
}
html 以这种方式包含多个嵌入图像。此方法是首选,因为使用 LinkedResources 通过电子邮件发送相同的 HTML在AlternateView .
foreach (var a in attachments)
{
//not production code
html += string.Format("<img src=\"cid:{0}\"></img>", a.Id.ToString());
}
但是,当生成 pdf 时,无法将图像 ID 与 src 链接起来。 img 的一部分标签。
最终,pdf 包含顶部的所有图像,然后是带有 <img src... 的 HTML忽略。
我已经阅读了几种使用 Paragraphs 或 ImageAbsolutePosition 的可能解决方案,但它们似乎不适合。
最佳答案
看this site ,看起来这可行。
编辑:
这是引用站点的代码和文本
一直在使用 iTextSharp 及其 HTMLWorker 类将一个 HTML 页面呈现为 PDF 的人知道我在说什么:如果 HTML 包含具有相对路径的图像,您可能会得到“友好”的蓝屏!
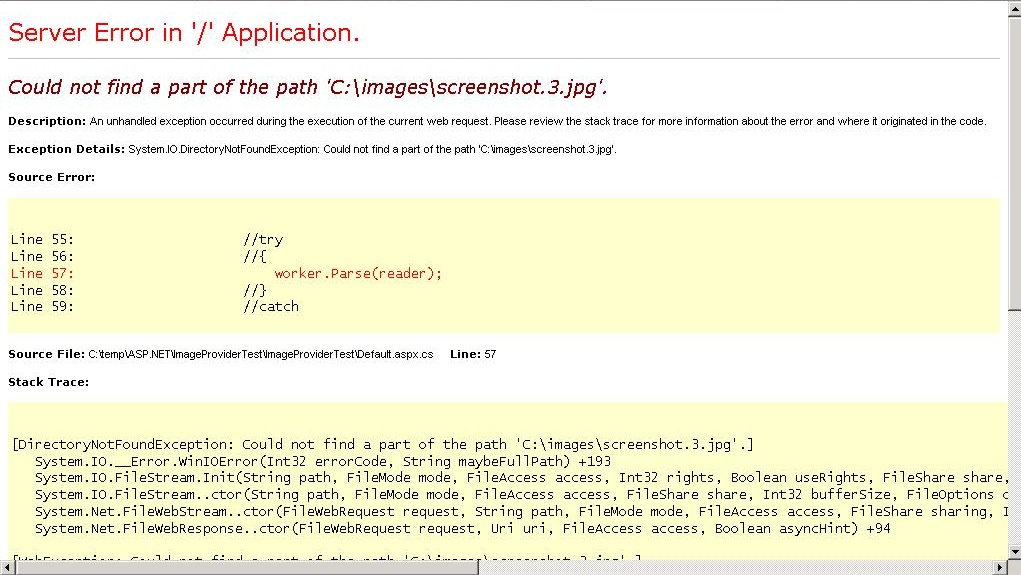
这意味着 iTextShap 尝试获取一张相对路径为“images/screenshot.3.jpg”的图像作为本地文件“C:\images\screenshot.3.jpg”,因此,该图像不存在. 在对如何向 iTextSharp 提供正确图像进行大量研究后,我发现有人提到了“IImageProvider”接口(interface),该接口(interface)使 iTextSharp 能够使用自定义方法查找图像。好吧,我已经使用 iTextSharp 5.0.2.0 完成了一个示例。你可以在这里下载。
首先,您必须创建一个实现 IImageProvider 接口(interface)的类:
public class CustomItextImageProvider : IImageProvider
{
#region IImageProvider Members
public iTextSharp.text.Image GetImage(string src, Dictionary<string,string> imageProperties, ChainedProperties cprops, IDocListener doc)
{
string imageLocation = imageProperties["src"].ToString();
string siteUrl = HttpContext.Current.Request.Url.AbsoluteUri.Replace(HttpContext.Current.Request.Url.AbsolutePath, "");
if (siteUrl.EndsWith("/"))
siteUrl = siteUrl.Substring(0, siteUrl.LastIndexOf("/"));
iTextSharp.text.Image image = null;
if (!imageLocation.StartsWith("http:") && !imageLocation.StartsWith("file:") && !imageLocation.StartsWith("https:") && !imageLocation.StartsWith("ftp:"))
imageLocation = siteUrl + (imageLocation.StartsWith("/") ? "" : "/") + imageLocation;
return iTextSharp.text.Image.GetInstance(imageLocation);
}
#endregion
}
之后,在呈现 HTML 内容之前,您必须将此图像提供程序指定为 HTMLWorker 类的“img_provider”接口(interface)属性:
HTMLWorker worker = new HTMLWorker(document);
Dictionary<string, object> interfaceProps = new Dictionary<string, object>() {
{"img_provider", new CustomItextImageProvider()}
};
worker.InterfaceProps = interfaceProps;
现在,当您呈现 HTML 时,它应该可以处理相关图像。
尽管这是为 ASP.Net 制作的一个示例,但主要思想是如何在呈现 HTML 时为 iTextSharp 创建一个自定义图像提供程序,它可以用于任何应用程序,此外,这不仅可以帮助您获取图像从相对位置,我已经使用它(显然有更多代码)从需要身份验证的 SharePoint 或站点获取图像。
关于c# - iTextSharp Html 到 Pdf 图像 src,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/13593758/