使用 Claudia JS 构建 Facebook Messenger 机器人并计划在 AWS Lambda 上托管。
我想问用户一系列问题。
当用户回复一个答案时,我需要保存它以备后用,一旦我获得了我需要的所有信息,我就会将答案传递给一个函数。
保存这些信息的最佳方式是什么?
我在考虑一些缓存层,例如 redis,但因为它存储在 RAM 中,所以当 lamda 服务器关闭时我会丢失它。 Mongodb 在连接时显然有很多开销,但至少会持久。
也许只是一个简单的 mySQL 服务器?
其他人是怎么做到的?我觉得我缺少一个简单的解决方案。
最佳答案
我将首先回答有关我是如何做的的部分:我正在使用 MongoDB。我考虑过你提到的想法,但出于同样的原因很快就划掉了内存中的解决方案(Memcached、Redis)。我的最终解决方案归结为关系数据库或像 MongoDB 这样的 noSQL。老实说,在我的项目规模下,我没有考虑过对 DB 类型之间的性能进行稳健的比较。
根据我的特殊功能“路线图”,由于 Mongo 的规范化结构,我决定在处理用户“对象”时采用更“OOP”的风格,而不必显式定义用户类。我知道 MySQL 也可以这样做,只是处理 json 数据对我和 flask 来说更“像对象”,即 user = getUserFromMongo ,这给了我一个 Python 字典,然后我就可以做 user['first_name']。下面的代码将解释这种简单性:
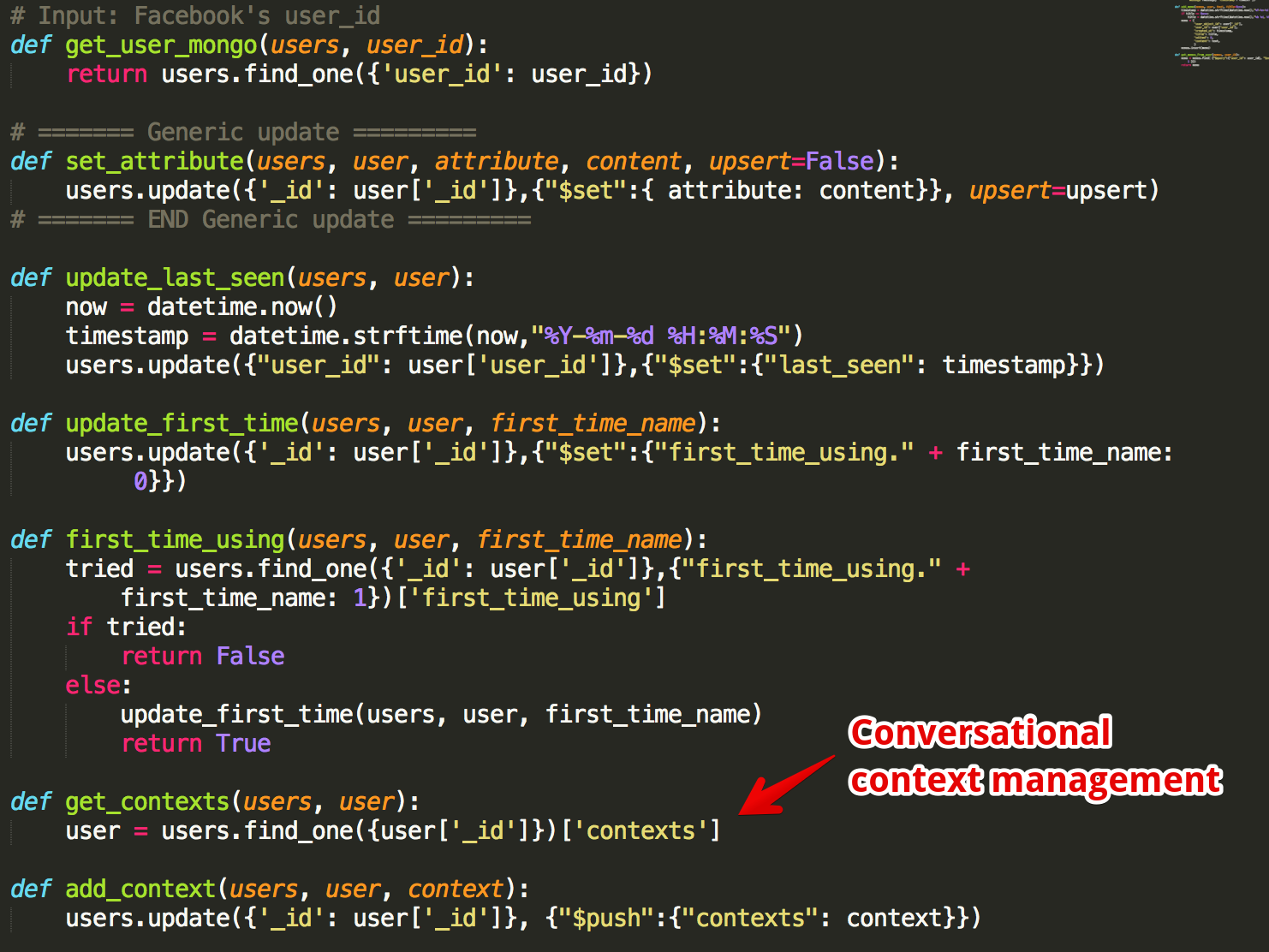 (不知何故,这感觉就像......不必为 Rails 中的简单数据库交互编写 SQL 命令)
(不知何故,这感觉就像......不必为 Rails 中的简单数据库交互编写 SQL 命令)
我在 MongoDB 上的用户对象数据
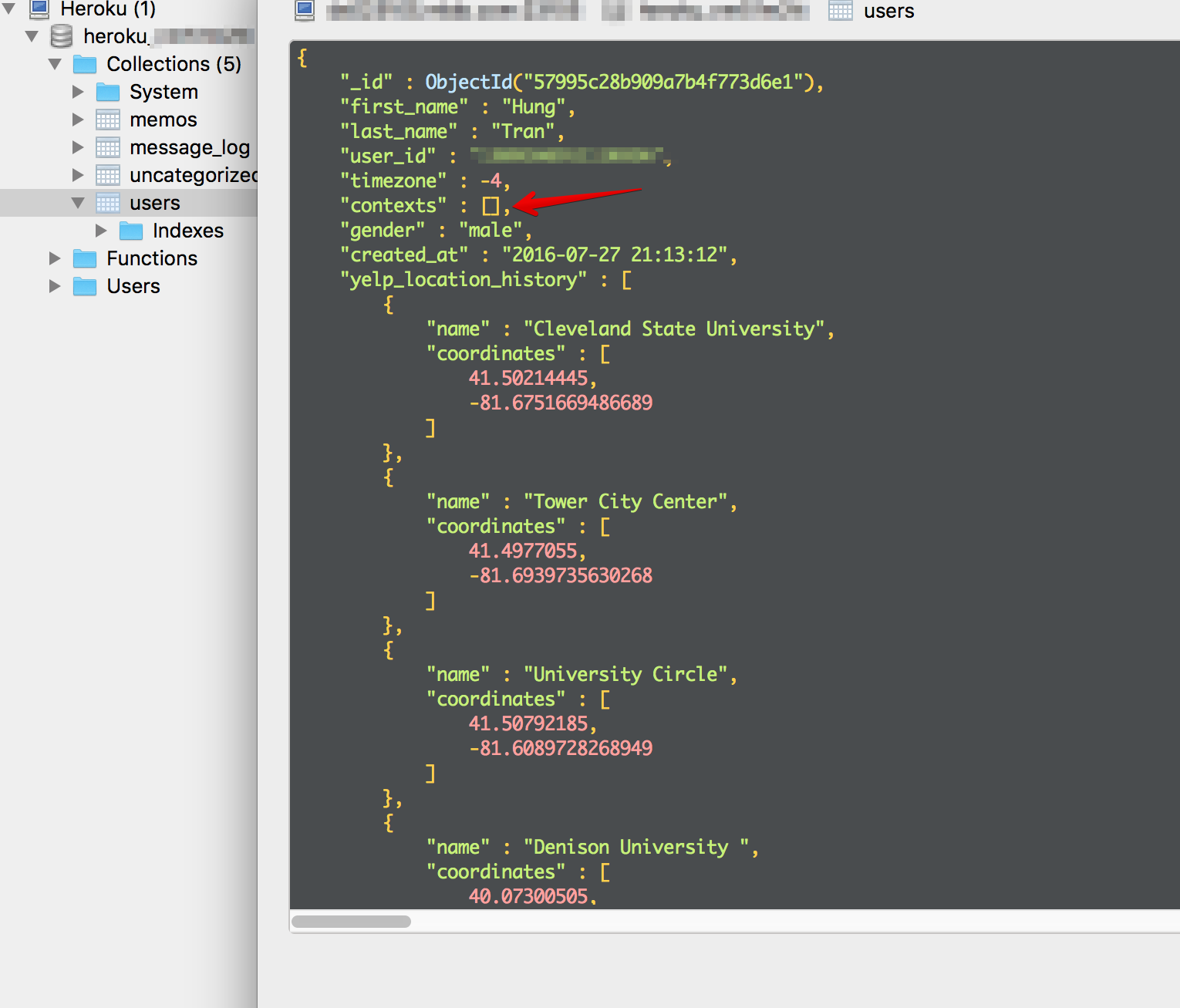
最后,关于我如何管理用户输入,我采用了 Wit.ai 的 context 概念。我不知道他们到底是怎么做到的,但对我来说,context 就是正在进行的对话目的类型。我像堆栈一样使用它,一旦当前上下文完成,就将其从用户的上下文数据中弹出。对于机器人收到的每条消息,程序都会获取当前上下文并引导流程。每当发生未知错误(异常处理)时,很可能是因为用户说的机器人听不懂的话,我也会清除 context 数据。
关于 MongoDB 的好处是我可以根据需要塑造 context 并将其视为一个对象。一个简单的像 {name: yelp-search, stage:ask-for-user-location},我想复杂的也可以建立在那个结构上。当然,context 的堆栈实现不处理具有复杂过去引用的复杂对话。
我put my project on Github如果你想看一看。
关于node.js - 在 Facebook 机器人聊天中存储用户答案的最佳方式?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/39462953/