我正在尝试在使用 Tensorflow 2 的 Keras API 的模型中计算每个时期之后每个类在二进制和多类(一个热编码)分类场景中的召回率。例如对于二进制分类,我希望能够做类似的事情
import tensorflow as tf
model = tf.keras.Sequential()
model.add(...)
model.add(tf.keras.layers.Dense(1))
model.compile(metrics=[binary_recall(label=0), binary_recall(label=1)], ...)
history = model.fit(...)
plt.plot(history.history['binary_recall_0'])
plt.plot(history.history['binary_recall_1'])
plt.show()
或者在多类场景中我想做类似的事情
model = tf.keras.Sequential()
model.add(...)
model.add(tf.keras.layers.Dense(3))
model.compile(metrics=[recall(label=0), recall(label=1), recall(label=2)], ...)
history = model.fit(...)
plt.plot(history.history['recall_0'])
plt.plot(history.history['recall_1'])
plt.plot(history.history['recall_2'])
plt.show()
我正在为一个不平衡的数据集开发一个分类器,并希望能够看到我的少数类的召回率在什么时候开始下降。
我在这里找到了多类分类器中特定类的精度实现 https://stackoverflow.com/a/41717938/373655 .我正在尝试将其调整为我需要的,但 keras.backend 对我来说仍然很陌生,因此非常感谢任何帮助。
我也不清楚我是否可以使用 Keras metrics(因为它们是在每批结束时计算的,然后取平均值)或者我是否需要使用 Keras callbacks(可以在每个纪元结束时运行)。在我看来它不应该对召回产生影响(例如 8/10 == (3/5 + 5/5)/2)但这就是召回在 Keras 2 中被删除的原因所以也许我遗漏了一些东西(https://github.com/keras-team/keras/issues/5794)
编辑 - 部分解决方案(多类分类) @mujjiga 的解决方案适用于二进制分类和多类分类,但正如@P-Gn 指出的那样,tensorflow 2 的 Recall metric开箱即用地支持多类分类。例如
from tensorflow.keras.metrics import Recall
model = ...
model.compile(loss='categorical_crossentropy', metrics=[
Recall(class_id=0, name='recall_0')
Recall(class_id=1, name='recall_1')
Recall(class_id=2, name='recall_2')
])
history = model.fit(...)
plt.plot(history.history['recall_2'])
plt.plot(history.history['val_recall_2'])
plt.show()
最佳答案
我们可以使用sklearn的classification_report和keras的Callback来实现。
工作代码示例(带注释)
import tensorflow as tf
import keras
from tensorflow.python.keras.layers import Dense, Input
from tensorflow.python.keras.models import Sequential
from tensorflow.python.keras.callbacks import Callback
from sklearn.metrics import recall_score, classification_report
from sklearn.datasets import make_classification
import numpy as np
import matplotlib.pyplot as plt
# Model -- Binary classifier
binary_model = Sequential()
binary_model.add(Dense(16, input_shape=(2,), activation='relu'))
binary_model.add(Dense(8, activation='relu'))
binary_model.add(Dense(1, activation='sigmoid'))
binary_model.compile('adam', loss='binary_crossentropy')
# Model -- Multiclass classifier
multiclass_model = Sequential()
multiclass_model.add(Dense(16, input_shape=(2,), activation='relu'))
multiclass_model.add(Dense(8, activation='relu'))
multiclass_model.add(Dense(3, activation='softmax'))
multiclass_model.compile('adam', loss='categorical_crossentropy')
# callback to find metrics at epoch end
class Metrics(Callback):
def __init__(self, x, y):
self.x = x
self.y = y if (y.ndim == 1 or y.shape[1] == 1) else np.argmax(y, axis=1)
self.reports = []
def on_epoch_end(self, epoch, logs={}):
y_hat = np.asarray(self.model.predict(self.x))
y_hat = np.where(y_hat > 0.5, 1, 0) if (y_hat.ndim == 1 or y_hat.shape[1] == 1) else np.argmax(y_hat, axis=1)
report = classification_report(self.y,y_hat,output_dict=True)
self.reports.append(report)
return
# Utility method
def get(self, metrics, of_class):
return [report[str(of_class)][metrics] for report in self.reports]
# Generate some train data (2 class) and train
x, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1)
metrics_binary = Metrics(x,y)
binary_model.fit(x, y, epochs=30, callbacks=[metrics_binary])
# Generate some train data (3 class) and train
x, y = make_classification(n_features=2, n_redundant=0, n_informative=2,
random_state=1, n_clusters_per_class=1, n_classes=3)
y = keras.utils.to_categorical(y,3)
metrics_multiclass = Metrics(x,y)
multiclass_model.fit(x, y, epochs=30, callbacks=[metrics_multiclass])
# Plotting
plt.close('all')
plt.plot(metrics_binary.get('recall',0), label='Class 0 recall')
plt.plot(metrics_binary.get('recall',1), label='Class 1 recall')
plt.plot(metrics_binary.get('precision',0), label='Class 0 precision')
plt.plot(metrics_binary.get('precision',1), label='Class 1 precision')
plt.plot(metrics_binary.get('f1-score',0), label='Class 0 f1-score')
plt.plot(metrics_binary.get('f1-score',1), label='Class 1 f1-score')
plt.legend(loc='lower right')
plt.show()
plt.close('all')
for m in ['recall', 'precision', 'f1-score']:
for c in [0,1,2]:
plt.plot(metrics_multiclass.get(m,c), label='Class {0} {1}'.format(c,m))
plt.legend(loc='lower right')
plt.show()
输出

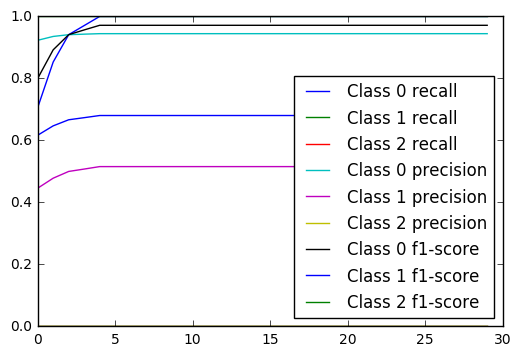
优点:
classification_report提供了很多指标- 可以通过将训练数据传递给
Metrics构造函数来计算关于训练数据的验证数据的指标。
关于python - 在 Tensorflow 2 中的每个纪元之后计算每个类的召回率,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/56382500/