我有一个格式的数据框
value
2000-01-01 1
2000-03-01 2
2000-06-01 15
2000-09-01 3
2000-12-01 7
2001-01-01 1
2001-03-01 3
2001-06-01 8
2001-09-01 5
2001-12-01 3
2002-01-01 1
2002-03-01 1
2002-06-01 8
2002-09-01 5
2002-12-01 19
(索引是日期时间)我需要逐年绘制所有结果以比较每 3 个月的结果(数据也可以是每月的),加上所有年份的平均值。
我可以轻松地分别绘制它们,但由于索引,它会根据索引移动图:
fig, axes = plt.subplots()
df['2000'].plot(ax=axes, label='2000')
df['2001'].plot(ax=axes, label='2001')
df['2002'].plot(ax=axes, label='2002')
axes.plot(df["2000":'2002'].groupby(df["2000":'2002'].index.month).mean())
所以这不是想要的结果。我在这里似乎有一些答案,但你必须连接,创建一个多索引和绘图。如果其中一个数据框有 NaN 或缺失值,它会非常麻烦。有 Pandas 的方法吗?
最佳答案
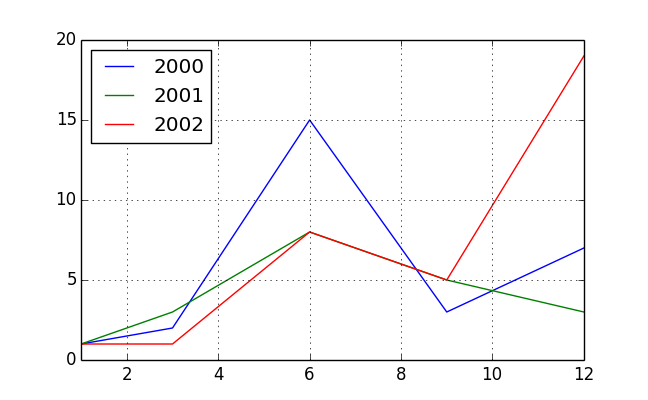
这是你想要的吗?改造后可以添加手段。
df = pd.DataFrame({'value': [1, 2, 15, 3, 7, 1, 3, 8, 5, 3, 1, 1, 8, 5, 19]},
index=pd.DatetimeIndex(['2000-01-01', '2000-03-01', '2000-06-01', '2000-09-01',
'2000-12-01', '2001-01-01', '2001-03-01', '2001-06-01',
'2001-09-01', '2001-12-01', '2002-01-01', '2002-03-01',
'2002-06-01', '2002-09-01', '2002-12-01']))
pv = pd.pivot_table(df, index=df.index.month, columns=df.index.year,
values='value', aggfunc='sum')
pv
# 2000 2001 2002
# 1 1 1 1
# 3 2 3 1
# 6 15 8 8
# 9 3 5 5
# 12 7 3 19
pv.plot()
关于python - 用年复一年的数据绘制 Pandas 数据框,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/30379789/