我已经坚持了一段时间,谷歌搜索似乎无济于事。
我正在阅读大量原始数据。一些变量作为对象出现,因为源使用字母出于各种原因丢失(我不关心)。
所以我想通过 pandas.to_numeric(___ ,error='coerce') 运行一个相当大的列子集,只是为了强制将它们转换为 int 或 float(同样,我这样做不太关心哪个,只关心它们是数字。
我可以轻松地逐列实现这一点:
df['col_name'] = pd.to_numeric(df['col_name'], errors='coerce')
但是,我有大约 60 个列我想像这样转换......所以我认为这会起作用:
numeric = ['lots', 'a', 'columns']
for item in numeric:
df_[item] = pd.to_numeric(df[item], errors='coerce')
我得到的错误是:
Traceback (most recent call last):
File "/Users/____/anaconda/lib/python2.7/site-packages/IPython/core/interactiveshell.py", line 2885, in run_code
exec(code_obj, self.user_global_ns, self.user_ns)
File "<ipython-input-53-43b873fbd712>", line 2, in <module>
df_detail[item] = pd.to_numeric(dfl[item], errors='coerce')
File "/Users/____/anaconda/lib/python2.7/site-packages/pandas/tools/util.py", line 101, in to_numeric
raise TypeError('arg must be a list, tuple, 1-d array, or Series')
TypeError: arg must be a list, tuple, 1-d array, or Series
我尝试了很多版本。这与列表或查看列表有关。当 for 循环简单地调用 df(item).describe()
根据我(还是新手)对 Python 的理解,这应该可行。我不知所措。 谢谢
最佳答案
首先,参见this answer
# Let
numeric = ['lots', 'a', 'columns']
选项 1
df[numeric] = df[numeric].apply(pd.to_numeric, errors='coerce')
选项 2
df.loc[:, numeric] = pd.to_numeric(df[numeric].values.ravel(), 'coerce') \
.reshape(-1, len(numeric))
示范
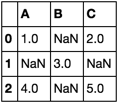
考虑数据框 df
df = pd.DataFrame([
[1, 'a', 2],
['b', 3, 'c'],
['4', 'd', '5']
], columns=['A', 'B', 'C'])
然后两个选项都高于 yield
关于python - 修改 Pandas 数据框中的许多列,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/39803254/