我测试了memcpy()的速度注意到速度在 i*4KB 处急剧下降。结果如下:Y轴是速度(MB/秒),X轴是memcpy()的缓冲区大小。 ,从 1KB 增加到 2MB。子图 2 和子图 3 详细说明了 1KB-150KB 和 1KB-32KB 的部分。
环境:
CPU : Intel(R) Xeon(R) CPU E5620 @ 2.40GHz
操作系统:2.6.35-22-generic#33-Ubuntu
GCC 编译器标志:-O3 -msse4 -DINTEL_SSE4 -Wall -std=c99
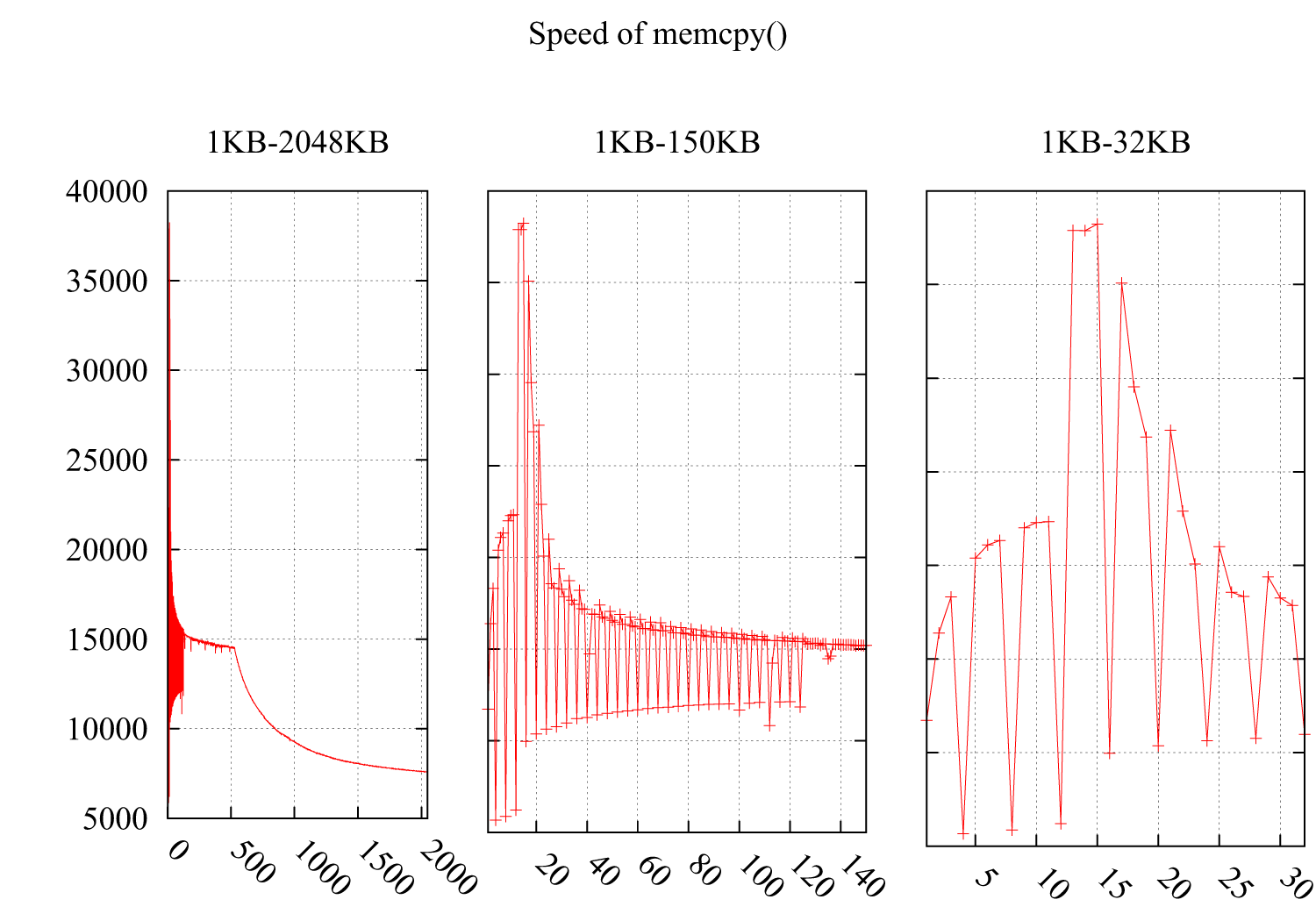
我想它一定与缓存有关,但我无法从以下缓存不友好的情况中找到原因:
由于这两种情况的性能下降都是由不友好的循环引起的,这些循环将分散的字节读入缓存,浪费了缓存线的其余空间。
这是我的代码:
void memcpy_speed(unsigned long buf_size, unsigned long iters){
struct timeval start, end;
unsigned char * pbuff_1;
unsigned char * pbuff_2;
pbuff_1 = malloc(buf_size);
pbuff_2 = malloc(buf_size);
gettimeofday(&start, NULL);
for(int i = 0; i < iters; ++i){
memcpy(pbuff_2, pbuff_1, buf_size);
}
gettimeofday(&end, NULL);
printf("%5.3f\n", ((buf_size*iters)/(1.024*1.024))/((end.tv_sec - \
start.tv_sec)*1000*1000+(end.tv_usec - start.tv_usec)));
free(pbuff_1);
free(pbuff_2);
}
更新
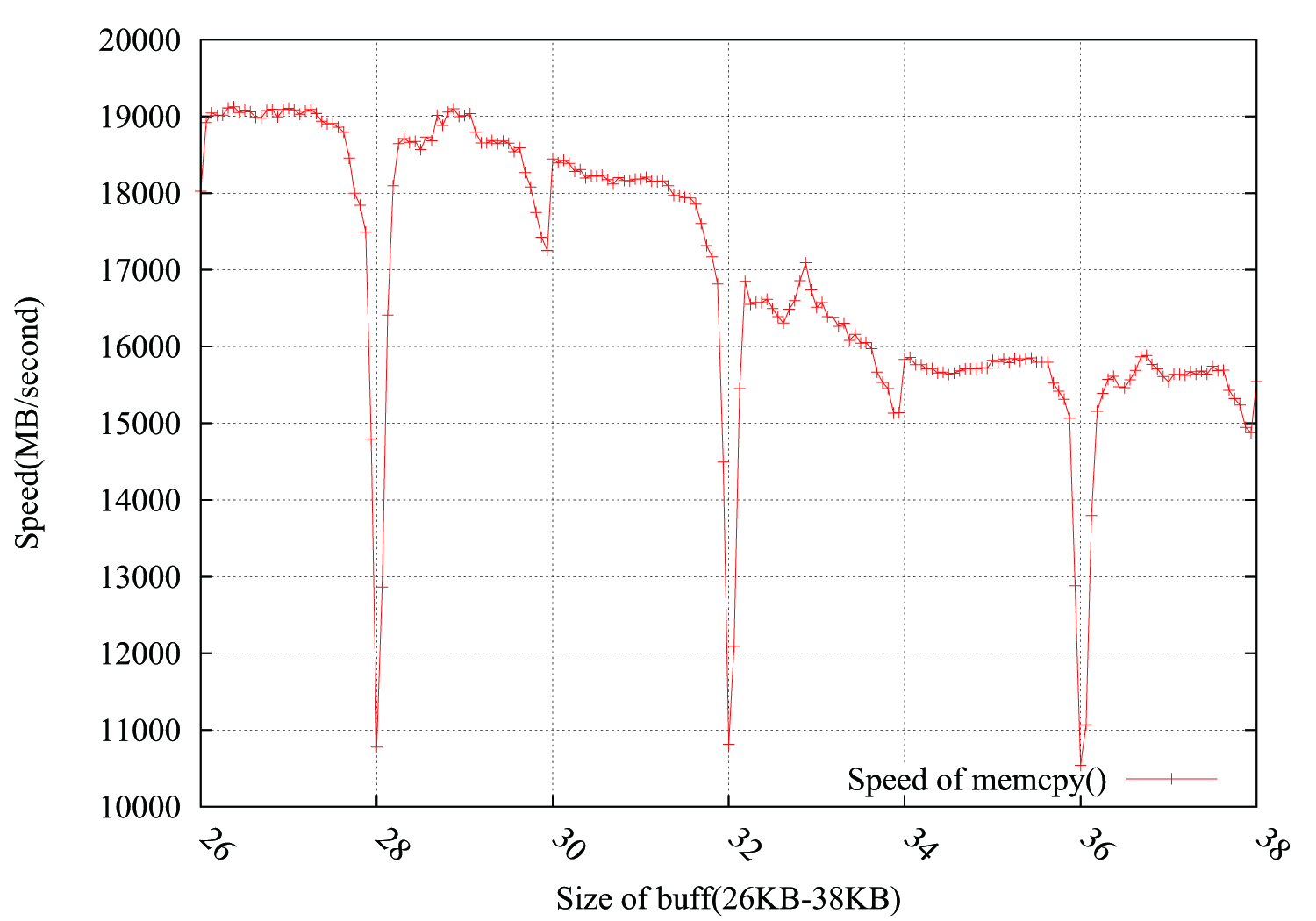
考虑到@usr、@ChrisW 和@Leeor 的建议,我更精确地重新进行了测试,下图显示了结果。缓冲区大小从26KB到38KB,我每隔64B测试一次(26KB、26KB+64B、26KB+128B、......、38KB)。每个测试在大约 0.15 秒内循环 100,000 次。有趣的是,下降不仅发生在 4KB 边界,而且出现在 4*i+2 KB,下降幅度要小得多。
聚苯乙烯
@Leeor 提供了一种填充 drop 的方法,在
pbuff_1 之间添加了一个 2KB 的虚拟缓冲区。和 pbuff_2 .它有效,但我不确定 Leeor 的解释。
最佳答案
内存通常以 4k 页组织(尽管也支持更大的尺寸)。您的程序看到的虚拟地址空间可能是连续的,但在物理内存中不一定如此。维护虚拟地址到物理地址的映射(在页面映射中)的操作系统通常也会尝试将物理页面保持在一起,但这并不总是可能的,并且它们可能会断裂(特别是在长时间使用时它们可能会偶尔交换) )。
当您的内存流跨越 4k 页面边界时,CPU 需要停止并获取新的翻译——如果它已经看到该页面,它可能会缓存在 TLB 中,并且访问被优化为最快,但如果这是第一次访问(或者如果您有太多页面供 TLB 保留),CPU 将不得不停止内存访问并开始对页面映射条目进行页面遍历 - 这相对较长,因为实际上每个级别自己读取的内存(在虚拟机上它甚至更长,因为每个级别可能需要在主机上进行完整的页面遍历)。
您的 memcpy 函数可能有另一个问题——当第一次分配内存时,操作系统只会将页面构建到页面映射中,但由于内部优化,将它们标记为未访问和未修改。第一次访问可能不仅会调用页面遍历,还可能会通知操作系统该页面将被使用(并存储到目标缓冲区页面中),这将需要向某些操作系统处理程序进行昂贵的转换。
为了消除这种噪音,分配缓冲区一次,执行多次复制,并计算分摊时间。另一方面,这会给你“温暖”的性能(即在缓存预热之后),所以你会看到缓存大小反射(reflect)在你的图表上。如果您想在不遭受分页延迟的情况下获得“冷”效果,您可能需要在迭代之间刷新缓存(只要确保您没有时间)
编辑
重读这个问题,你似乎在做一个正确的测量。我的解释的问题是它应该在4k*i之后显示逐渐增加。 ,因为在每次这样的下降时,您都会再次支付罚款,但随后应该享受免费乘车,直到下一个 4k。它没有解释为什么会有这样的“尖峰”,在它们之后速度恢复正常。
我认为您面临与问题中链接的关键步幅问题类似的问题 - 当您的缓冲区大小为 4k 时,两个缓冲区将与缓存中的相同集合对齐并相互碰撞。你的 L1 是 32k,所以一开始看起来不是问题,但假设数据 L1 有 8 种方式,它实际上是对相同集合的 4k 环绕,并且你有 2*4k 块具有完全相同的对齐方式(假设分配是连续完成的)所以它们在相同的集合上重叠。 LRU 不能完全按照您的预期工作就足够了,并且您将继续遇到冲突。
为了检查这一点,我会尝试在 pbuff_1 和 pbuff_2 之间分配一个虚拟缓冲区,使其大小为 2k 并希望它打破对齐。
编辑2:
好的,既然这有效,是时候详细说明了。假设您在 0x1000-0x1fff 范围内分配了两个 4k 数组和 0x2000-0x2fff . L1 中的 set 0 将包含 0x1000 和 0x2000 处的行,set 1 将包含 0x1040 和 0x2040,依此类推。在这些大小下,您还没有遇到任何抖动问题,它们都可以共存而不会溢出缓存的关联性。但是,每次执行迭代时,您都会有一个负载和一个访问同一个集合的存储 - 我猜这可能会导致硬件冲突。更糟糕的是 - 你需要多次迭代来复制一行,这意味着你有 8 个加载 + 8 个存储的拥塞(如果你向量化,则更少,但仍然很多),所有这些都针对同一个糟糕的集合,我很漂亮肯定有一堆碰撞隐藏在那里。
我也看到 Intel optimization guide对此有话要说(见 3.6.8.2):
4-KByte memory aliasing occurs when the code accesses two different memory locations with a 4-KByte offset between them. The 4-KByte aliasing situation can manifest in a memory copy routine where the addresses of the source buffer and destination buffer maintain a constant offset and the constant offset happens to be a multiple of the byte increment from one iteration to the next.
...
loads have to wait until stores have been retired before they can continue. For example at offset 16, the load of the next iteration is 4-KByte aliased current iteration store, therefore the loop must wait until the store operation completes, making the entire loop serialized. The amount of time needed to wait decreases with larger offset until offset of 96 resolves the issue (as there is no pending stores by the time of the load with same address).
关于performance - 为什么 memcpy() 的速度每 4KB 就会急剧下降?,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/21038965/