我有一个结构如下的学校表:
Id Classification XMLData
Where Id is a uniqueidentifier, Classification is a NVARCHAR and XMLData is XML.
此表有超过 100 万行。 XML 数据各不相同,因为它可能看起来像:
<student><grade></grade><standing></standing><gpa><gpa></student>
另一个例子:
<professor><subject></subject><years></years></professor>
但是,当我尝试使用此查询从表中检索 XML 数据时:
SELECT XMLData FROM School
查询大约需要 1 分钟来获取所有结果。
我尝试使用以下语法在 XML 列上放置主索引:
CREATE PRIMARY XML INDEX IXML_Value ON School (XMLData);
但似乎没有任何时间改进。检索仍然徘徊在 1 分钟左右。这是正常的吗?有没有办法让这个更快?
郑重声明,我的 School 表在主键 (Id) 上确实有一个聚簇索引。
最佳答案
Proving a Primary Index on an XML field does not make retrieval faster
比较没有索引和有索引的查询计划,您会发现它们完全相同,因此与您的查询没有区别。

如果您想查看索引的运行情况,您必须使用其中一个 xml Data Type Methods .
select XMLData.query('.') from dbo.School;
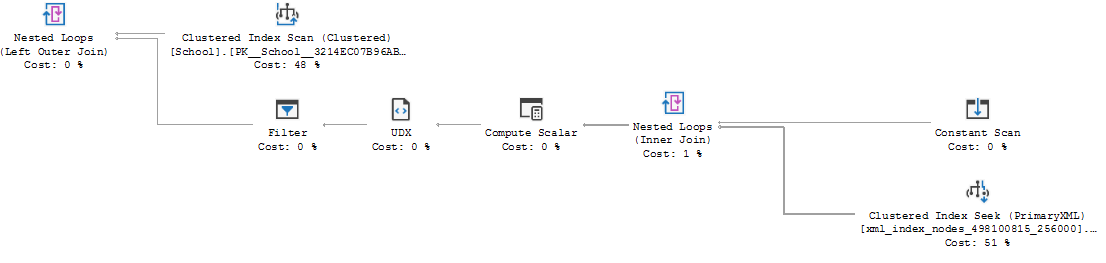
在右下方您可以看到正在使用的 XML 索引。如果仔细观察,您实际上会看到针对表 xml_index_nodes_4... 的聚簇索引查找。该表包含您的 XML 文档具有的所有预先分解的节点和值,查询计划的那部分检索构成您的 XML 的所有零碎部分,UDX 运算符负责将它们再次组合到一个 XML 文档中。我向你保证,在这种情况下你最好不要使用索引。直接检索 XML blob 更快。
Is there a way to get this faster?
不符合您在问题中指定的要求。您应该看看是否可能只检索 XML 的部分以及您的客户端完成其工作所需的行。
关于sql - 证明 XML 字段上的主索引不会使检索速度更快,我们在Stack Overflow上找到一个类似的问题: https://stackoverflow.com/questions/51081974/